Cross socket remote read may cause memory write
Updated: Oct 26th, 2023
Memory Directory
- only use one or more bit to encode “A/S/I” state
- these bits are hided in the ecc bits
- current implementation of hardware cache coherence, memory directory may not record the share list, just snoop all nodes
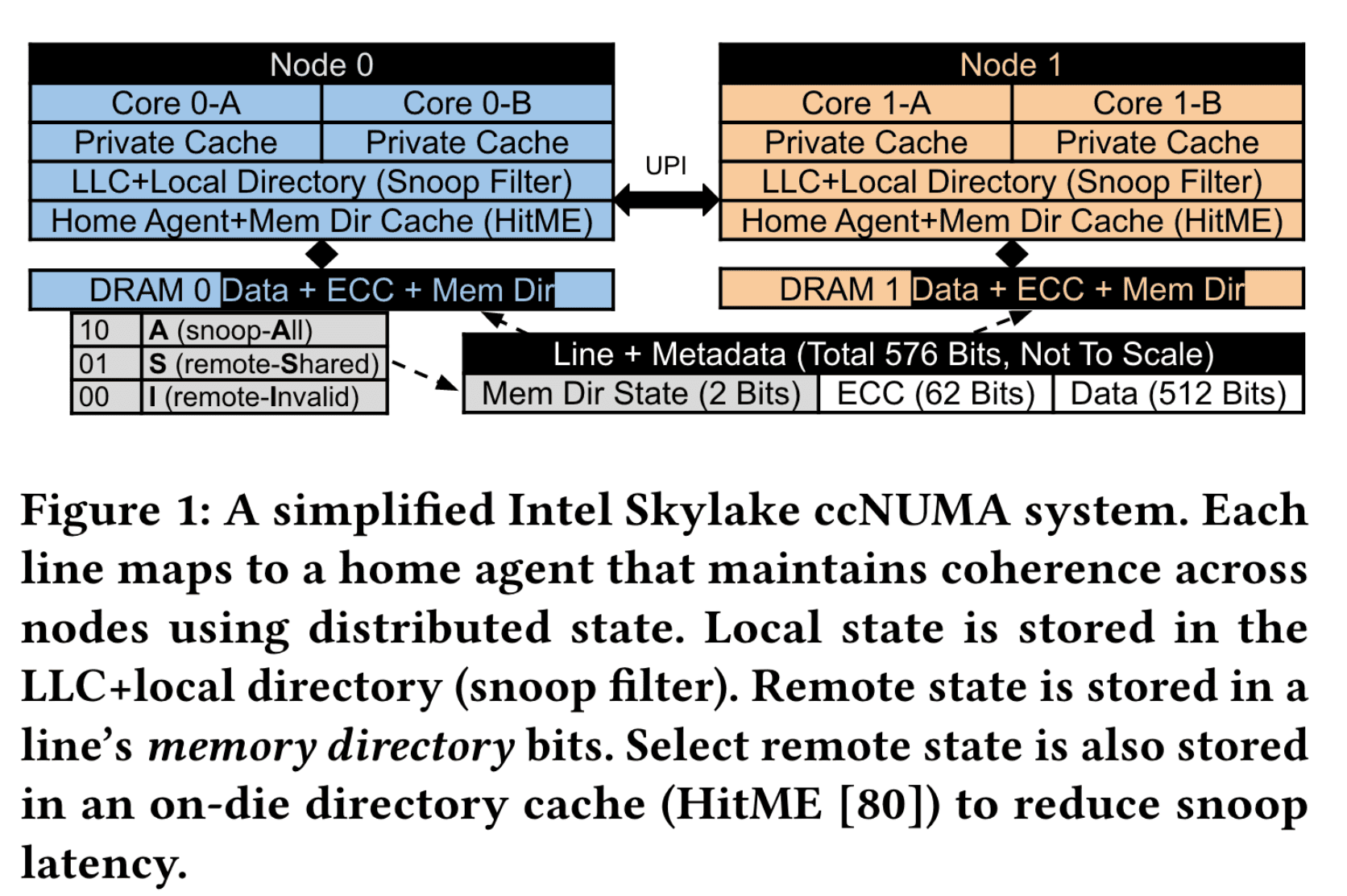 source[1]
source[1]
Cross socket remote read
- the remote cache hit
- remote cache can handle the state of the cache line, do not need to access and modify the memory directory
- remote cache miss
- need to reach the memory directory (A/S/I)
- access and modify the directory
- exclusive read : will change the “I” to “A”
- result in the modification of the memory directory, so that it write to memory.
- need to reach the memory directory (A/S/I)
Reference
-
SKL
- strange memory behavior - Intel Community
- A “memory directory” is one or more bits per cache line (hidden in the error correction bits) that indicate(s) whether a cache line might have a dirty copy in another socket.
- For local reads, if the bit shows “clean” (no possibility of a dirty
copy in another socket), then there is no need to issue a snoop request
to the other socket(s). If a snoop request was already sent (e.g., under
light loading of the UPI interface), there is no need to wait for the
response.
- For remote reads of data that is not in any cache, the default response is to provide the data in the “Exclusive” state. This is a protocol optimization that allows a core to write to an unshared cache line without requesting further permission. Unfortunately, this means that the “memory directory” bit must be set in that cache line in the home node, and the entire cache line must be written back to DRAM so that the updated “memory directory” bit is not lost.
-
Directory
Structure in Skylake Server CPUs - Intel Community
- read it all !
- For loads from local cores/caches, there is no need to set the bit because the distributed CHA/SF/L3 will be tracking the cache line state.
- For loads from remote caches, the decision depends on the state that
is granted when the cache line is sent to the requestor. By default, a
load request that does not hit in any caches will be returned in
“Exclusive” state.
- Exclusive state grants write permission without additional traffic.
- For snooped architectures, granting E state by default is a very
good optimization because
- Most memory references are to “private” memory addresses (stack, heap, etc), that are only accessed by one core
- A significant fraction of those private addresses will become store targets (but they are first accessed by a load, not a store)
- So this optimization eliminates the “upgrades” that would be required for the lines that are later store targets (if the initial state was “Shared”), and eliminates writebacks of data that is not modified (if the initial state was “Modified”)
- But, since E state lines can be modified, the memory controller has
to take the conservative route and set the “possibly modified in another
coherence domain” bit in the memory directory.
- If that bit was not set initially, the entire cache line has to be written back to memory to update the bit.
- If the bit was set initially, then there are too many special cases to consider here….
-
1524216121knl_skx_topology_coherence_2018-03-23.pptx
- P7:
- A Memory Directory is one or more bits per cache line in DRAM that tell the processor whether another socket might have a dirty copy of the cache line
- P8:
- Remote reads can update the directory, forcing the entire cache line to be written back to DRAM
- Increased memory traffic can be very confusing!
- E.g., read 1 GiB: measure 1 GiB Rd + 1 GiB Wr at memory controller
- P7:
- Solved: Turning off the cache coherence directory system wide in Intel Xeon Gold 6242 processor - Intel Community
- PACTree[2]
- We found that the directory coherence protocol is the root cause of the NUMA bandwidth meltdown. This is evident from Figure 2 as the performance of the FastFair plateaus when ran using Directory coherence protocol. This is because the current Intel processor architectures rely on the directory coherence protocol among NUMA domains, and it stores the directory information on the 3D-Xpoint media. Thus, on every remote read, the coherence state change ( e.g., from “Exclusive” to “Shared” state with bookkeeping the remote node ID) should be updated, causing a directory “write” operation to the 3DXpoint media. Because of this, the remote read bandwidth is significantly lower than the remote write bandwidth. This is detrimental because a remote read generates both read and write traffic.
- MOESI-prime[1]
- 3.3: We discovered that others had also reported unusually-high DRAM writes on Intel Skylake servers [46], and suspected memory directory (§2.3) writes as the cause. In particular, remote requests for a local cache line may require a DRAM write to track remote copies via memory directory state [78, 79] (e.g., remote-Invalid → snoop-All), incurring extra writes. Furthermore, because the on-die directory cache for select A lines uses write-on-allocate [80] (akin to write-through), even directory cache allocations immediately incur DRAM writes.
[1]
K.
Loughlin, S. Saroiu, A. Wolman, Y. A. Manerkar, and B. Kasikci,
“MOESI-prime: preventing coherence-induced hammering in commodity
workloads,” in Proceedings of the 49th Annual International
Symposium on Computer Architecture, New York, NY, USA, 2022, pp.
670–684, doi: 10.1145/3470496.3527427
[Online]. Available: https://dl.acm.org/doi/10.1145/3470496.3527427.
[Accessed: 25-Sept-2023]
[2]
W.-H. R. M. X. SanidhyaKashyap and C. Min,
“PACTree: A High Performance Persistent Range Index Using PAC
Guidelines,” 2021.
Notes mentioning this note
There are no notes linking to this note.