SOSP'21
Updated: Dec 6th, 2021
SOSP’21 会议已经落下帷幕,我来水一水今年SOSP’21会议的内容,简单看看视频,过一下这些文章的motivation。
Session 1: Byzantine fault-tolerance
Byzantine fault-tolerance 我来说一下我的理解。先说状态机复制,状态机复制是实现容错服务的常规方式,其简单来说就是要让多个状态机始终保持一致,对其中一个状态机做了修改,另一个也要跟着动,这几个状态机的状态都是保持一致的。为了保持一致, 这几个状态机需要相互通信互相告知自己的决策,但由于网络安全、网络错误等原因,通信的内容可能会发生错误(即拜占庭故事中故意传播错误信息的叛徒),这可能会导致多个本应当相同的副本变得不一样,即不一致了。这就是拜占庭将军问题,这个问题在很多地方都有说到过。
Basil: Breaking up BFT with ACID (transactions)
Florian Suri-Payer (Cornell University), Matthew Burke (Cornell University), Yunhao Zhang (Cornell University), Zheng Wang (Cornell University), Lorenzo Alvisi (Cornell University), Natacha Crooks (UC Berkeley)
BIDL: A High-throughput, Low-latency Permissioned Blockchain Framework for Datacenter Networks
Ji Qi (The University of Hong Kong), Xusheng Chen (The University of Hong Kong), Yunpeng Jiang (The University of Hong Kong), Jianyu Jiang (The University of Hong Kong), Tianxiang Shen (The University of Hong Kong), Shixiong Zhao (The University of Hong Kong), Sen Wang (Huawei Technologies Co., Ltd.), Gong Zhang (Huawei Technologies Co., Ltd.), Li Chen (Huawei Technologies Co., Ltd.), Man Ho Au (The University of Hong Kong), Heming Cui (The University of Hong Kong)
Kauri: Scalable BFT Consensus with Pipelined Tree-Based Dissemination and Aggregation
Ray Neiheiser (INESC-ID, IST, U. Lisboa and UFSC/DAS), Miguel Matos (INESC-ID, IST, U. Lisboa), Luís Rodrigues (INESC-ID, IST, U. Lisboa)
Session 2: Finding bugs
iGUARD: In-GPU Advanced Race Detection
iGUARD: In-GPU Advanced Race Detection
Aditya K Kamath (Indian Institute of Science), Arkaprava Basu (Indian Institute of Science)
随着GPU的发展,其内部支持的并行性越来越大,为了让线程在GPU中的同步有着更小的开销,现代GPU中有着更多的新型同步原语,这些新型同步原语能够帮助提升用户程序的性能,但也引入了更多的竞态(race)。
这里放一些例子。第一个例子是“Scoped synchronization”,其含义是将同步的范围限定在block/device/system中,通过缩小同步的范围来提升同步性能。相对应的,如果需要同步的线程没有使用足够大的scope用于同步,就会产生问题。第二个例子是“Independent thread scheduling (ITS)”,在2017年前,一个warp中的线程由于共用PC,其包含一个隐式的barrier,Volta架构提出了新的硬件功能ITS,每个县城有自己的PC,因此之前隐式的barrier不再保证,需要程序员自己增加barrier(syncwarp),这也可能会导致依赖传统功能的程序产生race。
提出了这个问题,作者实现了iGUARD系统用于在GPU中低开销,高效地实现race的监测。
Snowboard: Finding Kernel Concurrency Bugs through Systematic Inter-thread Communication Analysis
Snowboard: Finding Kernel Concurrency Bugs through Systematic Inter-thread Communication Analysis
Sishuai Gong (Purdue University), Deniz Altınbüken (Google Research), Pedro Fonseca (Purdue University), Petros Maniatis (Google Research)
这篇文章主要想解决的问题是:寻找内核的并发 BUG 。首先来一个例子,作者的演讲中举了一个简单的例子用来展示内核中可能存在的并发bug:两个内核线程都在操作同一个链表,一个内核线程删除了节点,另一个内核线程在遍历节点,遍历节点的线程可能就会遇到刚刚删除节点导致的NULL节点,导致panic。
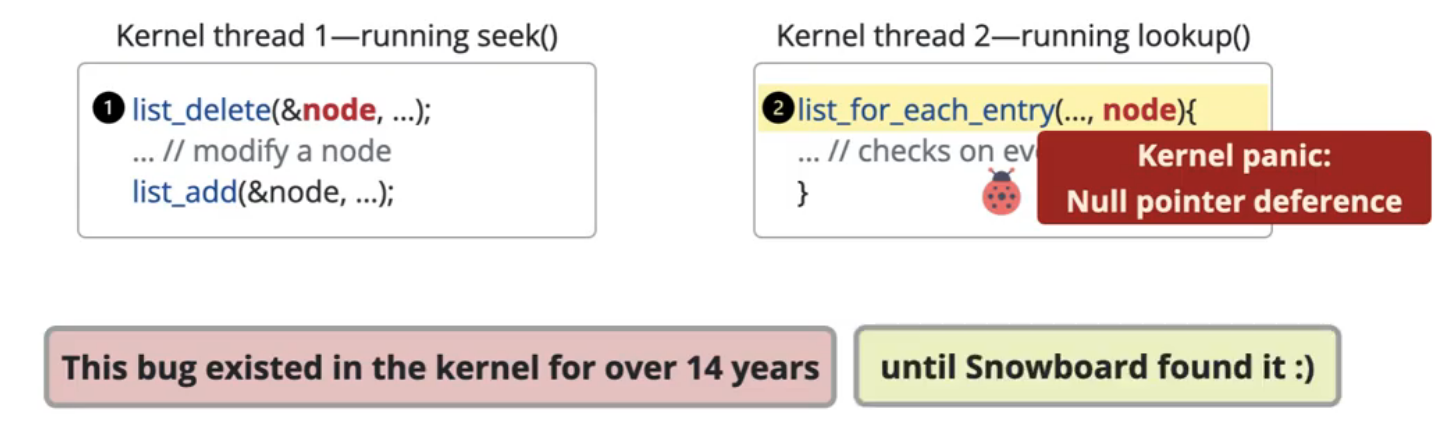
寻找这些内核问题的挑战在于:并发测试的搜索空间太大了,几乎不可能一一遍历进行测试,这个搜索空间大体现在1)系统调用太多了,不同的测试的组合数目已经很庞大了。2)不同的测试之间可能交错执行的可能同样很大。
这篇文章的motivation在于,搜索空间很大,但是我们可以寻找一些特征帮助我们寻找“更可能有bug”的并发测试样例。作者在这里寻找的特征是:“potential memory communication”(PMC)。利用这个特征,我们可以这样子提示测试:
- 若两个测试都需要访问相同的地址,则这两个测试的并发执行就有可能产生问题,记录为一个PMC。
- 会有很多PMC,作者通过聚类进行分析,并优先测试聚类最小(即不太常见)的PMC。
- 在这两个测试并发执行时,在每个待测的PMC处,只需要有两次测试分别代表先读后写或先写后读即可,其他的测试从PMC的角度是重复的,没有必要测。
Rudra: Finding Memory Safety Bugs in Rust at the Ecosystem Scale
Rudra: Finding Memory Safety Bugs in Rust at the Ecosystem Scale
Yechan Bae (Georgia Institute of Technology), Youngsuk Kim (Georgia Institute of Technology), Ammar Askar (Georgia Institute of Technology), Jungwon Lim (Georgia Institute of Technology), Taesoo Kim (Georgia Institute of Technology)
由于 Rust 能够在编译层面避免 Memory Safety Bug 的产生,而不需要高开销的垃圾回收机制,现在 Rust 作为一门系统编程语言已经有较高的热度。但在一些场景下,我们必须显式使用 unsafe Rust 来实现特定的功能,Rust 中的 Memory Safety Bug 也因此都来源于 unsafe Rust。
作者对 unsafe Rust 中可能发生的 Memory Safety Bug 进行了概括分类,分为下面三类:
- Panic safety bug
- 为了避免内存泄漏,Rust程序在发生Panic的时候会回收还存活的对象。在unsafe Rust中,用户可能会给对象分配uninitialize的内存,此时若发生panic,rust会调用uninitialize的对象的 destructor,此时就可能会执行未初始化的内存,造成任意代码执行漏洞。
- Higher-order invariant bug
- Higher-order invariant指的是用户提供的一些函数(如排序中的比较函数,字符串的convert函数),若程序对这些函数的假设有偏差,就可能会造成bug。
- 例子:join函数中,该程序假设字符串的convert函数产生的结果不会变,因此在计算长度和实际复制时都调用了convert函数,实际上用户完全可以自己定义返回结果可变化的convert的函数(如第一次返回长度为1的str,第二次返回长度为100的str),这就会造成bug。
- Send/Sync variance bug
- Send和Sync是两个Rust中用于实现并发安全的特性。
- 这个 Bug 我不太理解,不过大致的效果就是,Send/Sync不正确的实现,会导致 data race 。
Session 3: Consistency
一致性这个话题确实永远都做不完。先写写我对一致性问题的理解:软件中的一致性,一致指的是软件内部的数据结构都处于编程者期望的状态(如转账操作,编程者期望总金额不会变),但在进行一些操作的时候,软件中可能会有瞬时的不一致(同样是转账操作,转出和转入这两个操作肯定是先后发生的,当仅进行了传出还没进行转入时,总金额显然少了一部分,这就是中间瞬时的不一致状态),这些瞬时的不一致需要我们通过事务的支持,来避免其变成永久的不一致。
类似的不一致还可能会发生在很多地方,如文件系统、键值存储系统等等。在持久存储系统中,由于其数据需要永久存储,我们必须保证持久的数据始终保持一致的状态,然而程序可能会崩溃,服务器可能会宕机,电力供应可能会中断。持久的数据在意外后恢复的状态,我们希望其仍然满足一致性,这个就是崩溃一致性(也是持久一致性)。
Witcher: Systematic Crash Consistency Testing for Non-Volatile Memory Key-Value Stores
Witcher: Systematic Crash Consistency Testing for Non-Volatile Memory Key-Value Stores
Xinwei Fu (Virginia Tech), Wook-Hee Kim (Virginia Tech), Ajay Paddayuru Shreepathi (Stony Brook University), Mohannad Ismail (Virginia Tech), Sunny Wadkar (Virginia Tech), Dongyoon Lee (Stony Brook University), Changwoo Min (Virginia Tech)
这篇文章主要研究非易失性内存上的键值存储的崩溃一致性问题。众所周知,CPU 的 cache 是易失的(掉电后会丢失),这使得写入非易失性内存的数据需要通过额外的flush指令和fence指令来保证持久性和顺序性。这个区别于一般存储设备的特性让非易失性内存上的键值存储系统很容易产生崩溃一致性的bug。
过去的方法中,为了寻找这些bug,要么使用暴力搜索的方法,要么就是需要用户提供一些规则来帮助判断数据的不一致。前者费时费力(甚至由于开销过大而难以实现),而后者则是提出这些规则需要对应用有深刻的了解,另外无法保证用户提供的规则是正确的。
本文作者提出了 Witcher,一个不需要依赖用户提供规则,就能够高效寻找bug的系统,其实现的方法从直觉上可以通过下面两部分来理解:
- Inferring Likely-Correctness Conditions
- 用户不需要提供规则,Witcher会尝试从源代码和访存信息中推断可能成立的条件。Witcher会猜测该程序必须满足该条件才能保证一致性。
- 猜测方法:猜测持久顺序的依赖,如 Level Hash
中,在读的操作中,必须先读到token,然后才会读Key/Value,这里就发现了数据依赖:k/v
依赖 token 的值,这就可以推断出 k/v 的持久化必须在 写入token
的之前发生。
- 否则,如果写入token比k/v的持久化早,那么token就有可能先持久化,而此时k/v都没持久化,读操作中就有可能读到新的token,然后进一步读取“旧的/非持久化”的Key/Value,这就发生了不一致的情况。
- 另一种猜测需要猜多个操作间原子性的依赖。忽略。
- Output Equivalence Checking
- 上一步通过猜测得到了该键值存储中可能的一致性的规则,我们可以在现有的代码中尝试看是否有机会违背这样的一致性规则,若有机会,则将此作为一个测试样例,生成一个 Crash 的状态。
- 然后我们再去拿这个状态,去和“完成了崩溃操作”,和“没有完成崩溃时的操作”,这两个状态分别比较,如果没bug,应该总能匹配一个。但如果两个都匹配不上,那就是发现了bug。
最终效果看起来真挺厉害,找出了一堆 bug ,不过就是很好奇,未来 在 eADR 技术的支持下,cache 已经不会再丢数据了吧,到时候就主要根据 fence 来控制写入顺序来保证一致性了,这样是否会有新的挑战和问题呢?
Understanding and Detecting Software Upgrade Failures in Distributed Systems
Yongle Zhang (Purdue University), Junwen Yang (University of Chicago), Zhuqi Jin (University of Toronto), Utsav Sethi (University of Chicago), Kirk Rodrigues (University of Toronto), Shan Lu (University of Chicago), Ding Yuan (University of Toronto)
Crash Consistent Non-Volatile Memory Express
Xiaojian Liao (Tsinghua University), Youyou Lu (Tsinghua University), Zhe Yang (Tsinghua University), Jiwu Shu (Tsinghua University)
Session 4: Databases
TODO
Cuckoo Trie: Exploiting Memory-Level Parallelism for Efficient DRAM Indexing
Cuckoo Trie: Exploiting Memory-Level Parallelism for Efficient DRAM Indexing
Adar Zeitak (Tel Aviv University), Adam Morrison (Tel Aviv University)
这篇文章做的主题是:内存中的有序索引数据结构。传统的有序索引数据结构依赖指针来实现数据结构的组织,如搜索树使用指针指向左右儿子节点,B树使用指针指向子节点,Trie树同样使用指针。这些使用指针组织的树结构存在的共同问题是:指针追逐。CPU必须要一层层的对指针进行读取才能知道下一层的地址,这其中的多次访存行为必须串行执行,无法利用CPU的乱序执行特性提升访存并行性。
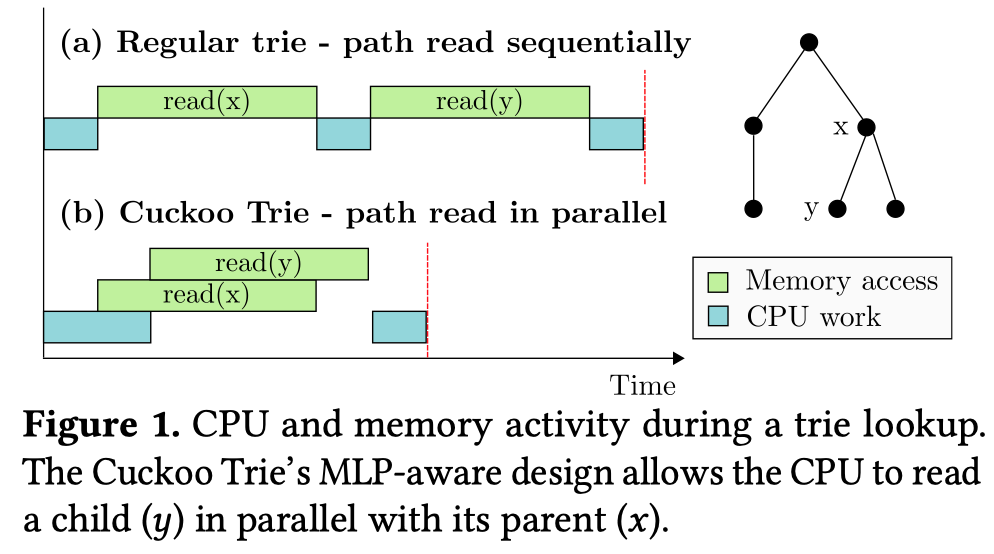
针对这个问题,作者提出了 Cuckoo Trie,一种能够利用访存并行性的DRAM有序索引。其基本的优化思路如上图所示,在 Cuckoo Trie 中,访问父子节点的操作是相互独立的,因此可以并行访存。显然,这个索引是面向读操作优化的。
- 如何让访问父子节点的操作相互独立起来?
- 让 Trie 中的节点,存放在 Cuckoo 哈希表中,key值就是这个节点当前对应的前缀。
- 如何进行读取操作?
- 若查找“BLINK”这一个元素,则可以并行的在哈希表中查找 “B”,“BL”,“BLI”,“BLIN”,“BLINK”这5个元素。
实话说,这个工作挺有意思的,但缺点也比较明显:
- 本质上还是一个哈希表,因此范围查询的性能是不如其他有序索引的。(逻辑上有序的内容在哈希中并没有有序的存放,访存局部性较差)
- 访存并行性上去了,然而访存次数大大增加。
Regular Sequential Serializability and Regular Sequential Consistency
Jeffrey Helt (Princeton University), Matthew Burke (Cornell University), Amit Levy (Princeton University), Wyatt Lloyd (Princeton University)
Caracal: Contention Management with Deterministic Concurrency Control
Dai Qin (University of Toronto), Angela Demke Brown (University of Toronto), Ashvin Goel (University of Toronto)
Session 5: Performance in the data center
这一个Session感觉主要和 RDMA 联系比较紧密。
The Demikernel Datapath OS Architecture for Microsecond-scale Datacenter Systems
The Demikernel Datapath OS Architecture for Microsecond-scale Datacenter Systems
Irene Zhang (Microsoft Research/University of Washington), Amanda Raybuck (University of Texas at Austin), Pratyush Patel (University of Washington), Kirk Olynyk (Microsoft Research), Jacob Nelson (Microsoft Research), Omar S. Navarro Leija (University of Pennsylvania), Ashlie Martinez (University of Washinton), Jing Liu (University of Wisconsin, Madison), Anna Kornfeld Simpson (University of Washington), Sujay Jayakar (Microsoft Research), Pedro Henrique Penna (Microsoft Research), Max Demoulin (University of Pennsylvania), Piali Choudhury (Microsoft Research), Anirudh Badam (Microsoft)
关于这篇文章的motivation,我想一作的blog会写得更直观易懂一些。
由于现代硬件吞吐量不断提升,延迟不断下降,传统内核的开销日趋明显,并成为系统的主要瓶颈,因此为了进一步提升系统的性能,旁路内核(kernel-bypass)成为一种主流的方式。现阶段,DPDK/SPDK/RDMA各自在网络、存储、远程内存访问上实现了kernel bypass,但是,现有的方案1)提供的接口较为底层,用户需要自行实现一些以往由OS负责的逻辑,2)不同的硬件需要不同的接口,用户适配较为困难。blog中提到了一个较容易理解的例子:内核tcp协议栈已经实现了流控、拥塞控制,用户直接用即可,无需担心丢包问题。但DPDK中并没有流控、拥塞控制(RDMA只有拥塞控制没有流控),如果网卡的buffer满了,可能会导致丢包的问题。这本应由OS处理的细节,现在却需要用户应用自行处理。
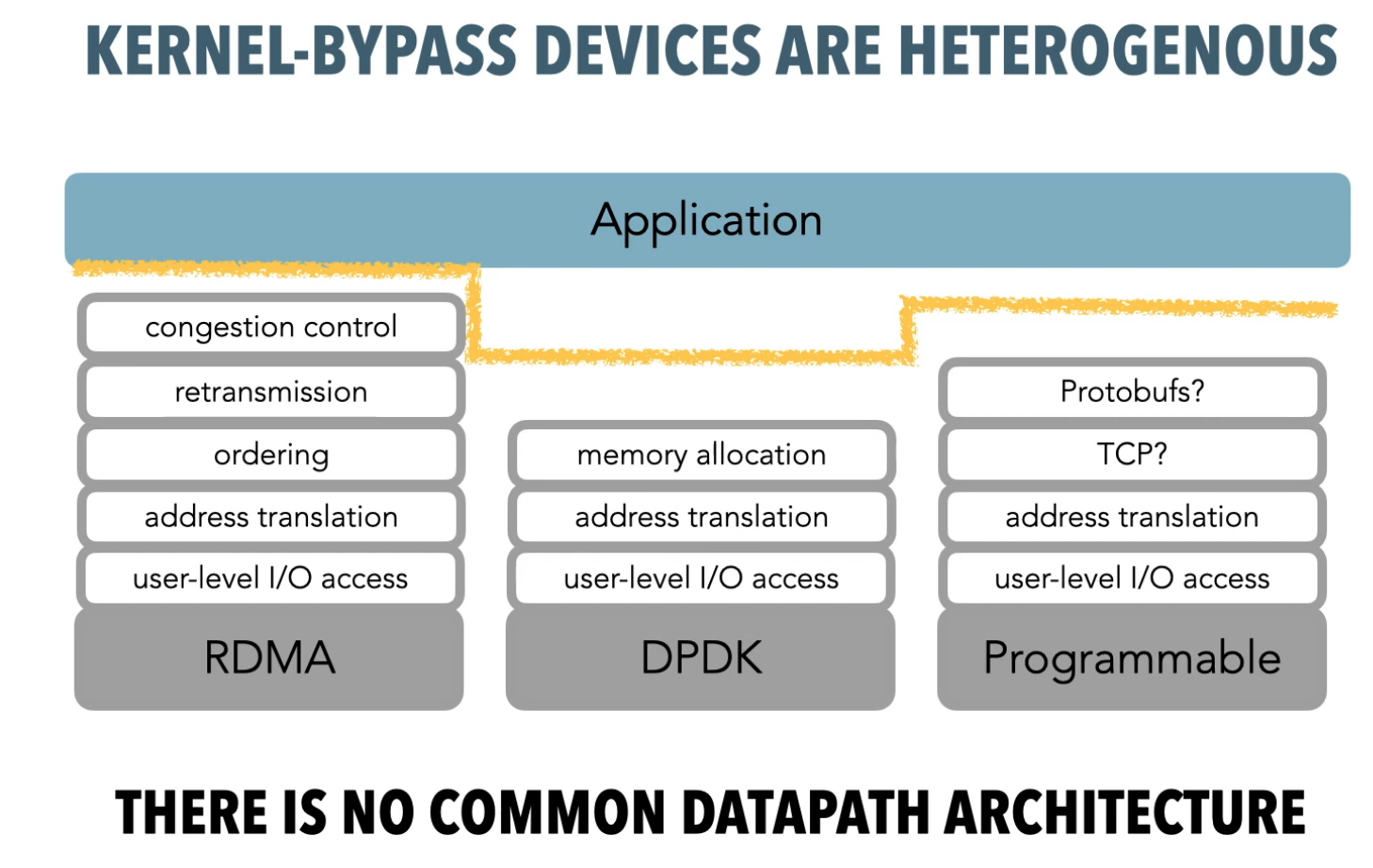
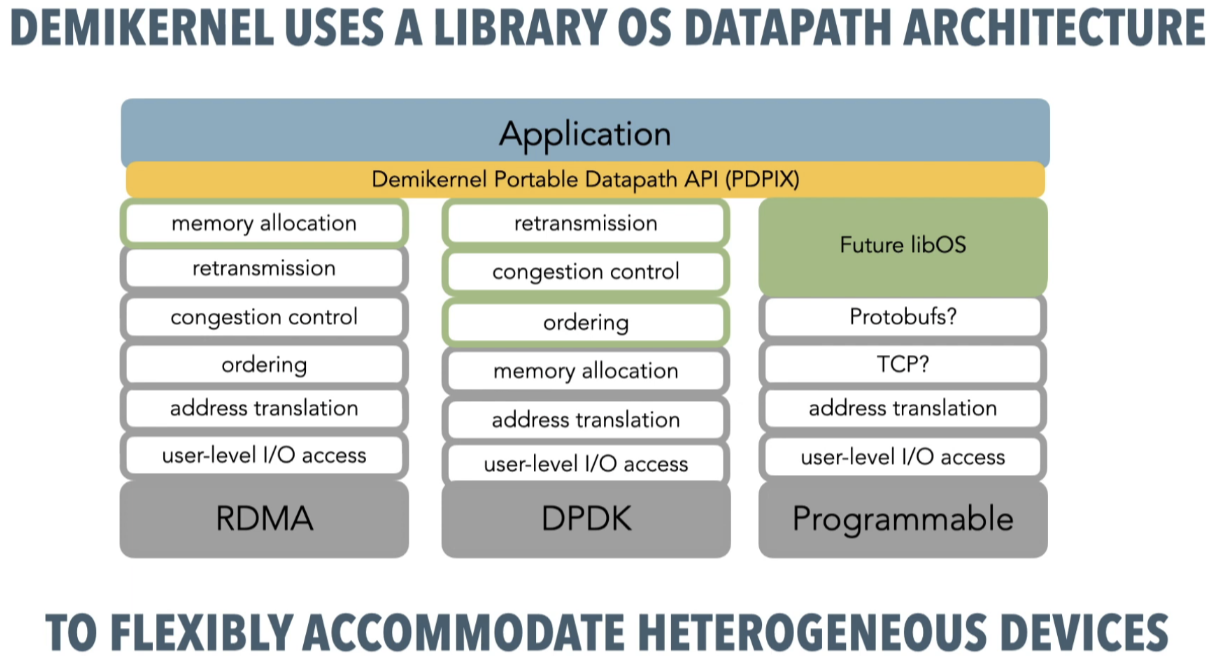
总结而言,如上图所示,现阶段旁路内核的方法实现的功能参差不齐,并不能够直接替代以往OS负责实现的接口。作者希望在用户态的library实现一个kernel-bypass下通用的接口,即PDPIX(相当于内核下的POSIX接口),然后在library下完成剩余所有OS应该要做的事情,并真正调用底层的kernel bypass的库。结果就是如下图所示:
Birds of a Feather Flock Together : Scaling RDMA RPCs with FLOCK
Sumit Kumar Monga (Virginia Tech), Sanidhya Kashyap (EPFL), Changwoo Min (Virginia Tech)
PRISM: Rethinking the RDMA Interface for Distributed Systems
PRISM: Rethinking the RDMA Interface for Distributed Systems
Matthew Burke (Cornell University), Sowmya Dharanipragada (Cornell University), Shannon Joyner (Cornell University), Adriana Szekeres (VMware Research), Jacob Nelson (Microsoft Research), Irene Zhang (Microsoft Research), Dan R. K. Ports (Microsoft Research)
最主要的 motivation 是RDMA编程下, one sided 和 two sided 之间的trade-off。这个 trade-off 可以通过下面例子来展示。这个例子展示的是使用 RDMA 从远程 KV 存储上获取value的过程。如果使用双边通信,一次网络传输将请求发到服务器端,然后服务器端就可以把这个操作完成并返回,消耗了一点CPU资源,不过只需要一次网络传输。如果使用单边通信,则需要两次单边通信分别进行才能够拿到value,这种方法不需要消耗 CPU,但是却需要两次网络传输。
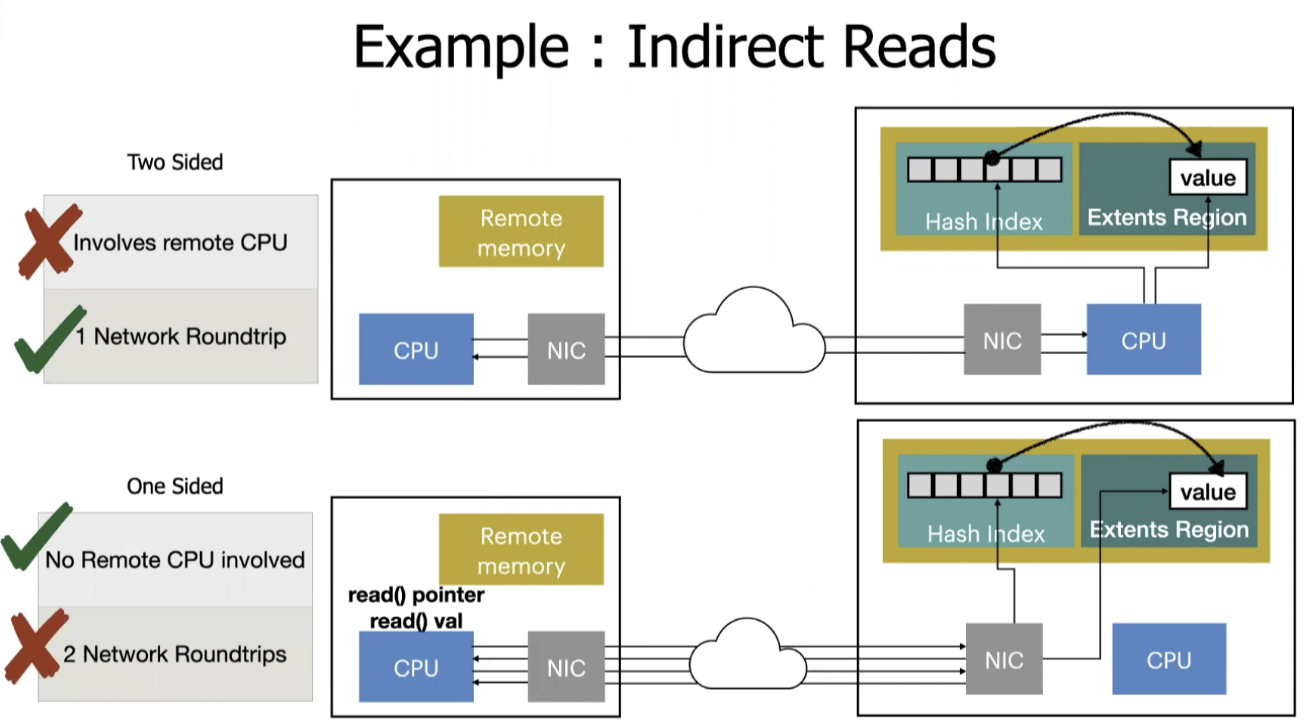
本文章认为,这种“CPU资源”和“网络通信”之间不可兼得的情况根源来自于RDMA的单边通信接口表达能力过于局限,其只能进行简单的READ/WRITE操作,任何略微复杂的操作都需要进行多次单边通信。要想缓解这个不可兼得的情况,作者认为,可以在 RDMA 原有的接口基础上,进行接口上的扩展,定义额外的几个RDMA通信原语,并尝试用这几个通用的 RDMA 通信原语去表达更多复杂的逻辑,从而优化尽可能多的应用。
Session 6: Flash storage
Kangaroo: Caching Billions of Tiny Objects on Flash
Kangaroo: Caching Billions of Tiny Objects on Flash
Best Paper Award
Sara McAllister (Carnegie Mellon University), Benjamin Berg (Carnegie Mellon University), Julian Tutuncu-Macias (Carnegie Mellon University), Juncheng Yang (Carnegie Mellon University), Sathya Gunasekar (Facebook), Jimmy Lu (Facebook), Daniel Berger (University of Washington/ Microsoft Research), Nathan Beckmann (Carnegie Mellon University), Gregory R. Ganger (Carnegie Mellon University)
这篇文章的标题非常直白:在 Flash 上缓存十亿级别的小对象。首先大量tiny object(100B左右的对象)是非常常见的,在 facebook 还有 twitter 上都需要缓存大量的小对象(如博文,一条博文就几十个字母),然后由于数量过于庞大,用DRAM、NVM又太浪费钱了,所以公司想要用Flash(即固态硬盘)来做这个缓存。
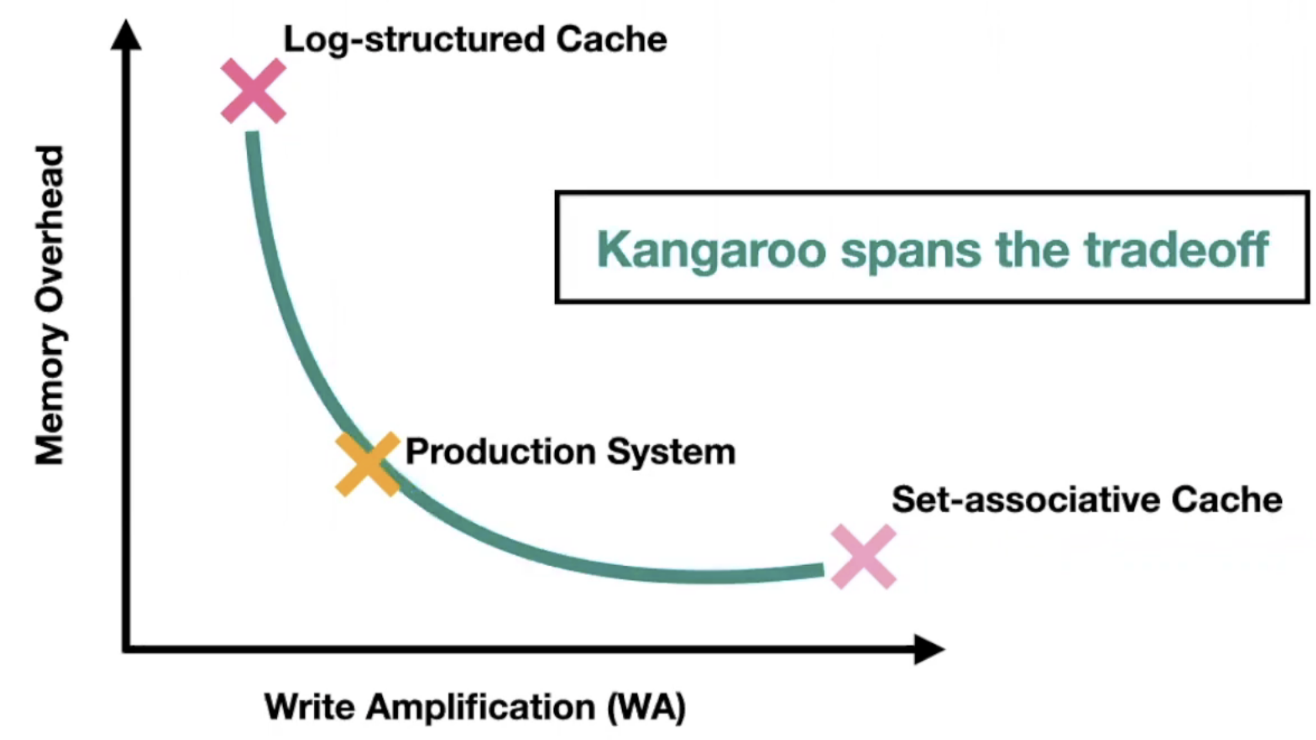
固态硬盘来做缓存是合适的,一方面是容量足够大,价格便宜,另一个方面是随机读写性能好,但是固态硬盘有一个固有的缺点:随机小写会导致写放大,这点让我们在固态上设计缓存系统时面临这样的一个权衡:“使用日志写能够最大限度的避免写放大,但由于写入的位置完全没有规律,需要在内存给所有对象维护一个完整的索引。而如果使用组相连映射的方式在固态上设计缓存,则内存中仅需维护读优化的bloom filter即可,但由于小对象远远小于固态的存储粒度(100B << 4096B),这又会带来大量的写放大。这篇文章提出的Kangaroo就是希望能够在这个trade-off中找到一个较合适的中间态。
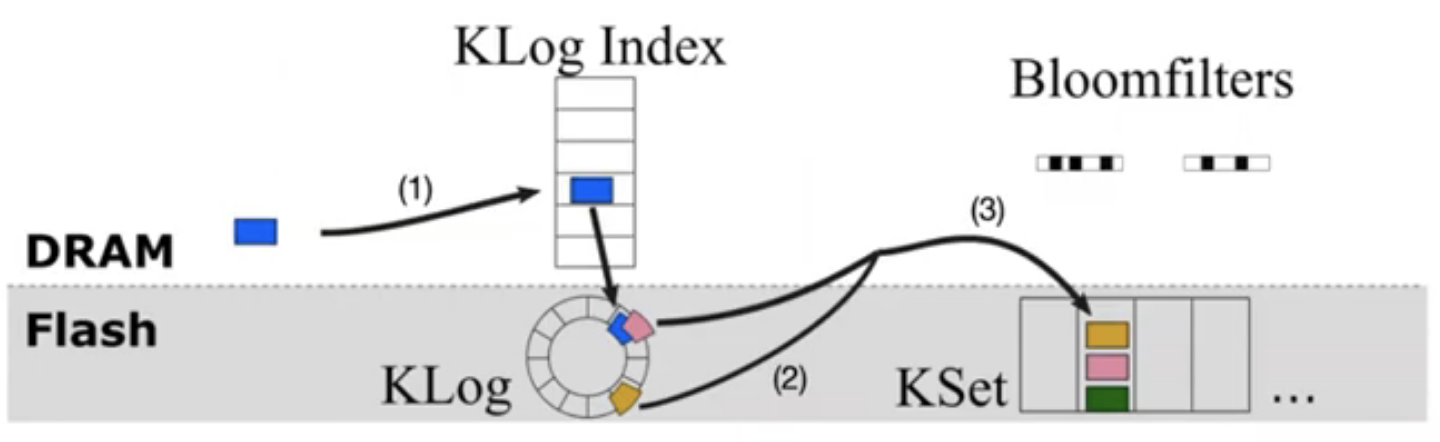
这个系统大致的思路是:对于trade-off的两端(log-structure/set-asociative cache),kangaroo 想要结合两者的优点,而尽量避免其带来的缺点。一方面,用一小部分 SSD 以 Log-structure 的方式组织 cache,并对这一小部分维护一个内存索引,在小部分的内存占用的同时优化写放大,另一方面,剩余的大部分固态,则用 set-associative cache 的方式来组织,避免了大部分内存占用,klog会定期间一部分数据刷到 kset 。
在这个架构下,作者提出了三个技术用于进一步优化:
- 如何把 klog 上的数据刷到 kset ?一个一个object刷到 kset 肯定会带来写放大,作者提出的方法是:把在 klog 中,落到 kset 中同一个 set的object一起刷,并设定一个阈值,要超过 n 个能一起刷的才刷。为了实现这个,klog 中的哈希索引针对此进行了优化,相同set中的数据,在log中会落到同一个bucket中,方便查同一个set中的object。
- 后面还有两个方法是用于优化cache 的命中率的,暂时就不详细写了。
IODA: A Host/Device Co-Design for Strong Predictability Contract on Modern Flash Storage
IODA: A Host/Device Co-Design for Strong Predictability Contract on Modern Flash Storage
Huaicheng Li (University of Chicago and Carnegie Mellon University), Martin L. Putra (University of Chicago), Ronald Shi (University of Chicago), Xing Lin (NetApp), Gregory R. Ganger (Carnegie Mellon University), Haryadi S. Gunawi (University of Chicago)
这篇文章想要解决的问题是:SSD阵列上由于SSD中的内部操作(如GC)导致的长尾延迟。众所周知,一般SSD的延迟可以低至10us,但如果SSD在GC时,延迟可以涨到20~40ms,更为严重的事,主机端不知道SSD什么时候在GC,这意味着SSD的延迟是“不可预测”的,时而10us,时而40ms。这个问题在 SSD 阵列上更为严重,阵列上的每个I/O请求都可能设计多个SSD盘,这其中只要有一个在GC,那么就会拖垮整个I/O请求的延迟。
解决这个问题的契机,来源于 NVMe 的一套新扩展:“NVMe Predictable Latency Mode”(NVMe PLM),这套扩展将 SSD 的状态分为两种,一种是 Deterministic Window,另一种是 Non-Deterministic Window,主机可以切换不同的状态,SSD只会在Non-Deterministic Window中进行GC等会影响延迟的事情。这套扩展让主机能够了解和控制SSD的内部行为,但同时该扩展也存在一些不足。

本文的工作在NVMe PLM 的基础上,对NVMe的接口进行了扩展,以支持对SSD更细粒度的控制和查询,从而能够让SSD阵列上的I/O操作几乎不受GC的影响,达到可预测的程度。
- Fail-of-slow, the SSD should fast-fail an I/O if it contends with GC.
- TW Coordination: SSDs take turns to perform GCs.
FragPicker: A New Defragmentation Tool for Modern Storage Devices
FragPicker: A New Defragmentation Tool for Modern Storage Devices
Jonggyu Park (Sungkyunkwan University), Young Ik Eom (Dept. of Electrical and Computer Engineering/College of Computing and Informatics, Sungkyunkwan University)
这篇文章关注Flash存储上的碎片整理。碎片一般来说,指的是一个文件的所有数据没有连续的存放在盘上,而是以小数据碎片的方式散乱在放置在盘上。文件碎片化,在机械硬盘上会带来的主要问题是增加了寻道时间,而一般来说,由于固态硬盘并没有寻道这个过程,因此文件碎片化在固态上可能影响不大,因此一般都不会在固态硬盘上进行碎片整理。
但这篇文章打破了上述成见,作者提出:文件碎片化在固态上同样会影响性能,但影响性能的主要原因和HDD不同。文件碎片化可以体现为两个指标,一个是碎片大小(frag size),另一个是碎片间的距离(frag distance)。无论是机械还是固态,碎片大小都对其性能有明显影响(即便碎片大小都至少是4KB),而碎片间的距离则仅在机械硬盘上有影响。固态上的碎片会影响性能,可以这样解释:I/O请求增加。原本一个连续的I/O请求变成了多个随机的I/O请求,内核层面开销大。

motivation有了,那现在的碎片整理工具存在什么问题?1)整理粒度为文件,需要将一整个文件重写一遍,IO量大。(FragPicker可以做到仅整理影响显著的部分块) 2)不同的文件系统各自实现碎片整理工具(FragPicker不需要修改内核,且与文件系统实现无关)

总结一下,这篇文章的创新点在于发现了固态上的碎片整理可以忽略碎片间的距离,因此在进行碎片整理的时候不需要把整个文件的数据重写一遍,只需整理部分对性能影响较显著的小碎片即可。最终实现的FragPicker仅需更少的I/O量就能达到和现在的碎片整理工具相当的效果。
Session 9: Non-volatile memory
HeMem: Scalable Tiered Memory Management for Big Data Applications and Real NVM
HeMem: Scalable Tiered Memory Management for Big Data Applications and Real NVM
Amanda Raybuck (University of Texas at Austin), Tim Stamler (University of Texas at Austin), Wei Zhang (Microsoft), Mattan Erez (University of Texas at Austin), Simon Peter (University of Texas at Austin)
这篇文章提出了一种在用户态实现分层内存管理的方法。相比起DRAM,NVM具备更大的存储密度,NVM+DRAM组合而成的分层内存让用户应用可以使用更大的内存。但由于NVM和DRAM之间的性能存在较大差异,若对分层内存的管理不当,应用的性能可能会受到较大影响。
现有的方法主要由三种,一种是Optane PM自带的Memory Mode,其将DRAM作为PMEM的cache,完全由硬件来实现分层内存的管理,另一种是OS将PM看做一个NUMA节点,其由OS来实现内存页之间的迁移,这两种方法都能够透明的实现分层内存的管理,但都存在一些问题,如硬件实现的cache难以实现复杂的冷热分离策略,OS实现的策略依赖页表中的特定bit来存放访问信息,这种方法在内存容量进一步增大的情况下难以进一步扩展。而作者采取的方法是直接使用 daxfs 上的文件mmap出一段空间,然后使用纯用户态的方法来管理。
为了管理分层内存,作者提出的HeMem需要实现1)冷热内存页的识别,以及2)内存页的迁移。为了识别冷热内存,作者没有依赖页表中的数据结构,而是使用Processor event based sampling(PEBS)来对访存行为进行采样分析,低开销的对冷热内存页进行区分,在内存页的迁移中,作者使用了DMA实现异步的内存迁移。另外该系统中还有一些其余的策略。
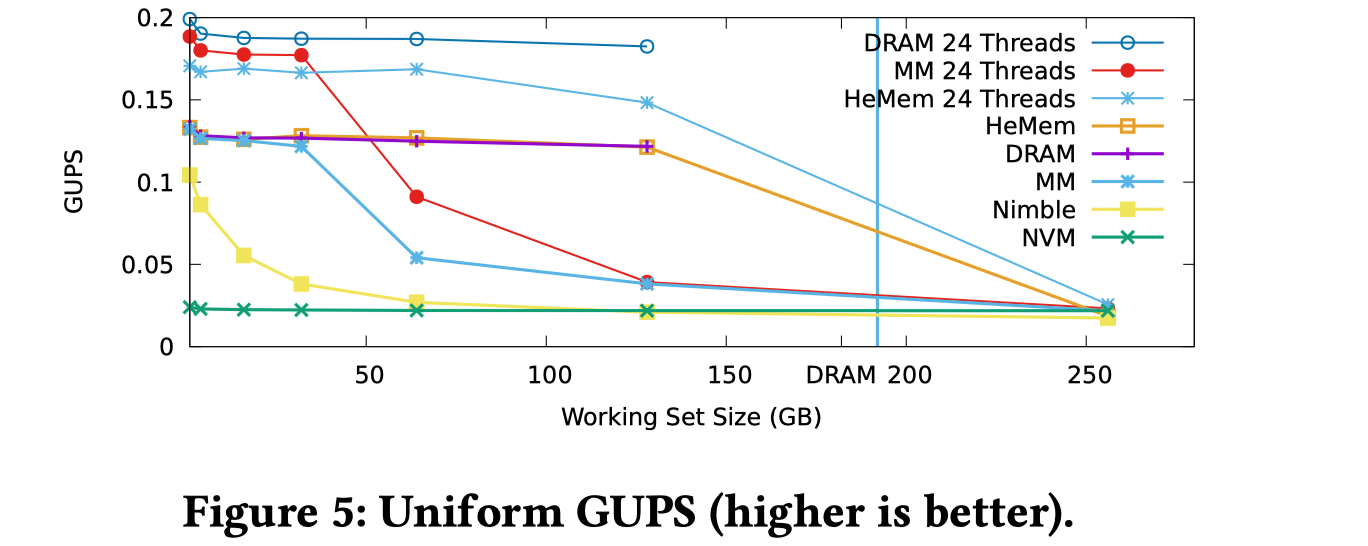
最终该系统能够在 GUPS 这一个应用中,实现性能比Memory Mode好且性能尽可能接近纯DRAM的水平。
J-NVM: Off-heap Persistent Objects in Java
J-NVM: Off-heap Persistent Objects in Java
Anatole Lefort (Télécom SudParis - Institut Polytechnique de Paris), Yohan Pipereau (Télécom SudParis - Institut Polytechnique de Paris), Kwabena Amponsem Boateng (Télécom SudParis - Institut Polytechnique de Paris), Pierre Sutra (Télécom SudParis - Institut Polytechnique de Paris), Gaël Thomas (Télécom SudParis - Institut Polytechnique de Paris)
Java中有很多应用需要操作大量的持久数据(如各种hadoop、spark之类),这些应用能从现在新型的存储,NVM中受益,但目前在Java中使用NVM仍然面临一些问题。目前主流有两种使用方式,一种是把NVM视为一种堆外的空间,在堆外使用JNI/pmdk等方式来访问,这种方式的问题是数据在堆内外移动需要转换,带来额外开销,同时增加了一个daxfs中间层,另一种是直接把NVM的空间放在堆里面,由JAVA的GC来管理,这种方法避免了堆内外转换的开销,但现阶段的GC在堆容量不断增大后带来的开销巨大。,后者观点可以通过下图的两个实验来证明,可以看到,当堆变大后,无论是总完成时间,还是操作的平均延迟,由GC带来的开销已经变成了系统的主要瓶颈。

前面两种方法各有好处也有利弊,这篇文章想要实现的便是把上面两种方法的好处都拿到,避免其弊端,因此提出的J-NVM,需要实现以下两个目标:
- Off-heap,其GC不由Java管理,相反,是用户手动管理。
- 原因:需要手动删除的情况其实很少见。
- Persistent Objects in
Java,希望NVM中的对象就如同原生Java堆中的对象一样,能够直接访问而不需要转换。
- 原因:两种不同的表示需要进行转换,这个开销成为了限制性能的主要瓶颈。
这篇文章是怎么做的呢?其提供了一个给Java类做标记的“Persistent?”,用于标志该类一定是持久化的,然后通过代码生成器,便将该类转换成在PM上跑的类了,其对成员的操作会直接操作PM,其方法会自动实现failure-atomic特性(即要么执行完毕,要么一点都没执行)。
PACTree: A High Performance Persistent Range Index Using PAC Guidelines
PACTree: A High Performance Persistent Range Index Using PAC Guidelines
Wook-Hee Kim (Virginia Tech), R. Madhava Krishnan (Virginia Tech), Xinwei Fu (Virginia Tech), Sanidhya Kashyap (EPFL), Changwoo Min (Virginia Tech)
这篇文章讲的是NVM上的持久范围查询索引数据结构的设计。该文章的贡献主要分为这两部分:
- 提出了PAC Guidelines,用于从NVM设备的特性中概括一些帮助设计索引数据结构的指导意见。
- 提出了一个新的范围查询索引:“PACTree”,其性能几乎比其他文章中测过的索引都要高很多。
对于第一部分,其实很多观察大家也都有过一些了解,我认为其最有创新性的一点是:发现了跨NUMA访问PM性能暴跌的根本原因是 directory coherence protocol 。在远程访问PM时,cache一致性相关的信息会写在PM中,导致性能急剧下降。因此在后面的大实验中,作者的测试环境配置是:snoop coherence protocol。另外一点是关于读操作的带宽,作者分析了B+树和Trie树的区别,认为Trie的设计让读取操作更加节省PM有限的带宽。
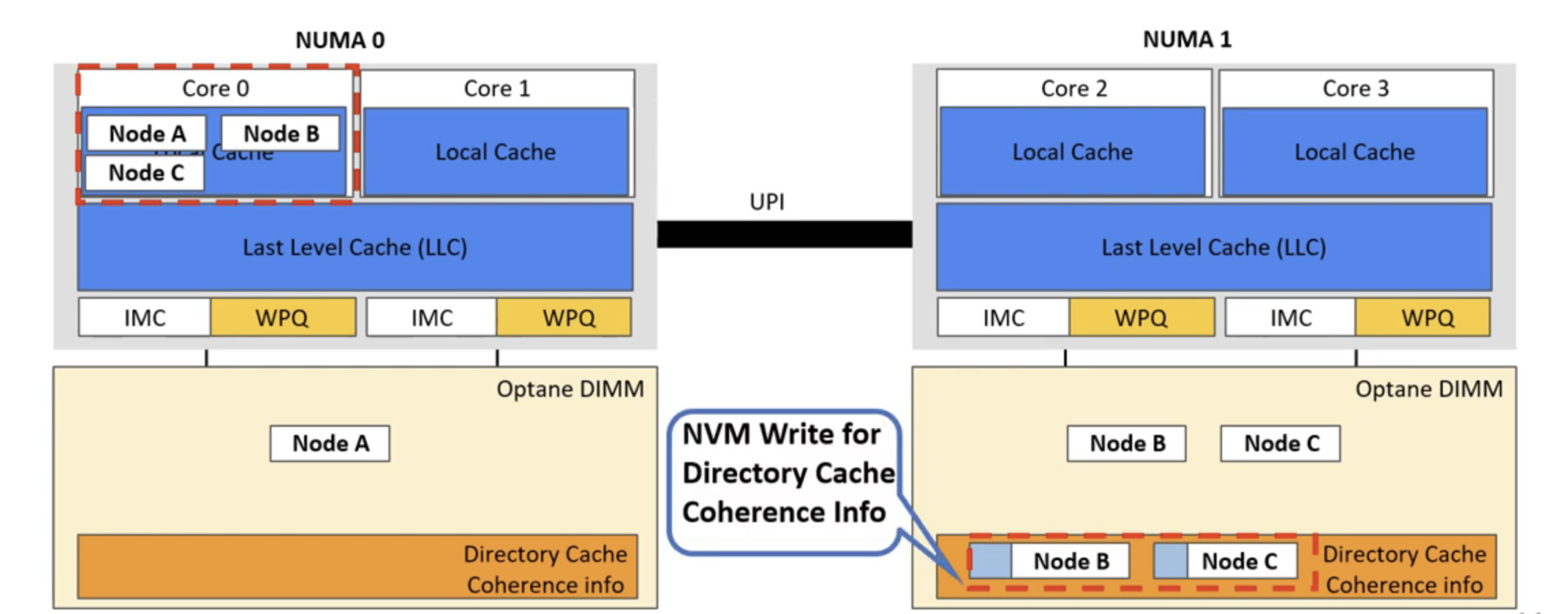
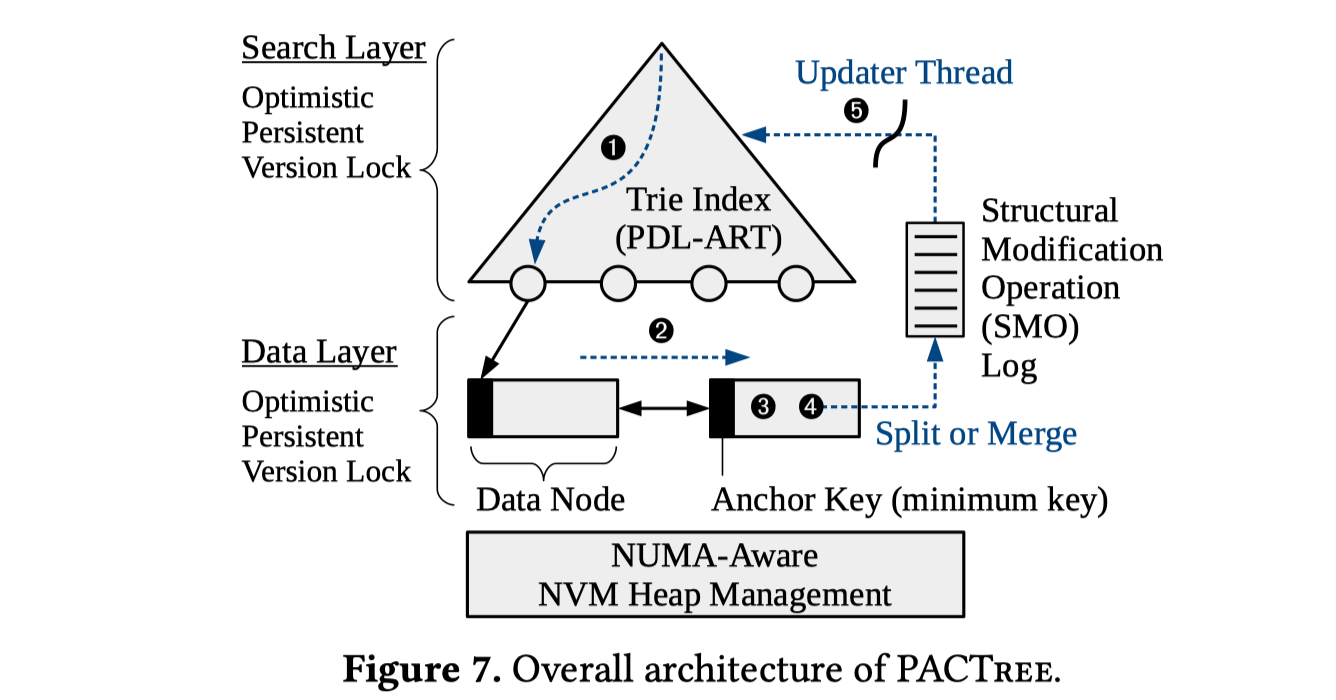
对于文章中提出的新型的范围查询索引“PACTree”,是一个叶子结点为Trie树节点,而根节点构造和B+Tree类似的结构。其设计的思路是:
- 考虑到读取操作中,Trie树的构造能更省带宽,因此在搜索层使用了Trie树的构造
- 考虑到NVM的延迟较高,树中的SMO延迟较大,作者将叶子结点和内部节点之间的操作解耦合。叶子结点以双向链表的方式构造,插入数据时,如果遇到节点已满,需要分裂的情况,则直接在双向链表中创建新节点插入即可。此时虽然内部节点的Trie树没有更新结构,其仍然能够搜索到。然后将Trie中的更新(需要SMO)交给一个背景线程来实现,避免SMO在关键路径中影响延迟。
Session 10: Replication
Exploiting Nil-Externality for Fast Replicated Storage
Exploiting Nil-Externality for Fast Replicated Storage
Aishwarya Ganesan (VMware Research), Ramnatthan Alagappan (VMware Research), Andrea Arpaci-Dusseau (University of Wisconsin–Madison), Remzi Arpaci-Dusseau (University of Wisconsin–Madison)
Nil-Externality是一种接口的性质,该性质的含义是:调用该接口时,该接口可能会改变存储系统内部的状态,但其不会返回存储系统现在的状态(也就是不需要外部化存储系统的状态)。有很多存储系统都有这样性质的接口,如RocksDB中的put操作,memcache的set操作。这样的性质允许操作先持久化,然后不同副本间再对执行顺序进行协商和同步(推迟同步协商和排序的过程)。这能够对现在的共识协议的设计有所帮助:对Nil-Externality感知的共识协议相比起每次操作都要马上同步并协商执行顺序的传统Paxos,能够提升性能。

Geometric Partitioning: Explore the Boundary of Optimal Erasure Code Repair
Yingdi Shan (Tsinghua University), Kang Chen (Tsinghua University), Tuoyu Gong (Tsinghua University), Lidong Zhou (Microsoft Research), Tai Zhou (Alibaba Group), Yongwei Wu (Tsinghua University)
Rabia: Simplifying State-Machine Replication Through Randomization
Haochen Pan (Boston College), Jesse Tuglu (Boston College), Neo Zhou (Boston College), Tianshu Wang (Boston College), Yicheng Shen (Boston College), Xiong Zheng (UT Austin), Joseph Tassarotti (Boston College), Lewis Tseng (Boston College), Roberto Palmieri (Lehigh University)
TODO
Session 16: Smart NICs
Xenic: SmartNIC-Accelerated Distributed Transactions
Henry N. Schuh (University of Washington), Weihao Liang (University of Washington), Ming Liu (University of Wisconsin at Madison/VMware Research), Jacob Nelson (Microsoft Research), Arvind Krishnamurthy (University of Washington)
使用SmartNIC卸载一些分布式事务的处理逻辑,提升分布式事务的性能。
LineFS: Efficient SmartNIC Offload of a Distributed File System with Pipeline Parallelism
LineFS: Efficient SmartNIC Offload of a Distributed File System with Pipeline Parallelism
Best Paper Award
Jongyul Kim (KAIST), Insu Jang (KAIST), Waleed Reda (Université catholique de Louvain / KTH Royal Institute of Technology), Jaeseong Im (KAIST), Marco Canini (KAUST), Dejan Kostić (KTH Royal Institute of Technology), Youngjin Kwon (KAIST), Simon Peter (University of Texas at Austin), Emmett Witchel (The University of Texas at Austin and Katana Graph)
这篇文章做的是非易失内存上的分布式文件系统。其最主要的背景是:分布式文件系统的CPU开销随着存储设备变快,日趋增加,为PM而设计的分布式文件系统中,由于网络开销比PM读写延迟还大,因此PM上的分布式文件系统往往会使用直接写本地的方式来避免网络带来的开销,但这增加了客户端处的CPU开销。以PARSEC enchmark中的streamcluster为例,在运行assise并进行文件系统性能测试时,streamcluster的执行时间增加了72%。
由于CPU开销大,但又不能放弃client-local的DFS设计,作者提出,可以把DFS中的一些任务卸载到智能网卡中,这样就能够降低客户端CPU的开销,但卸载到智能网卡中,DFS的设计又会面临这两个挑战:
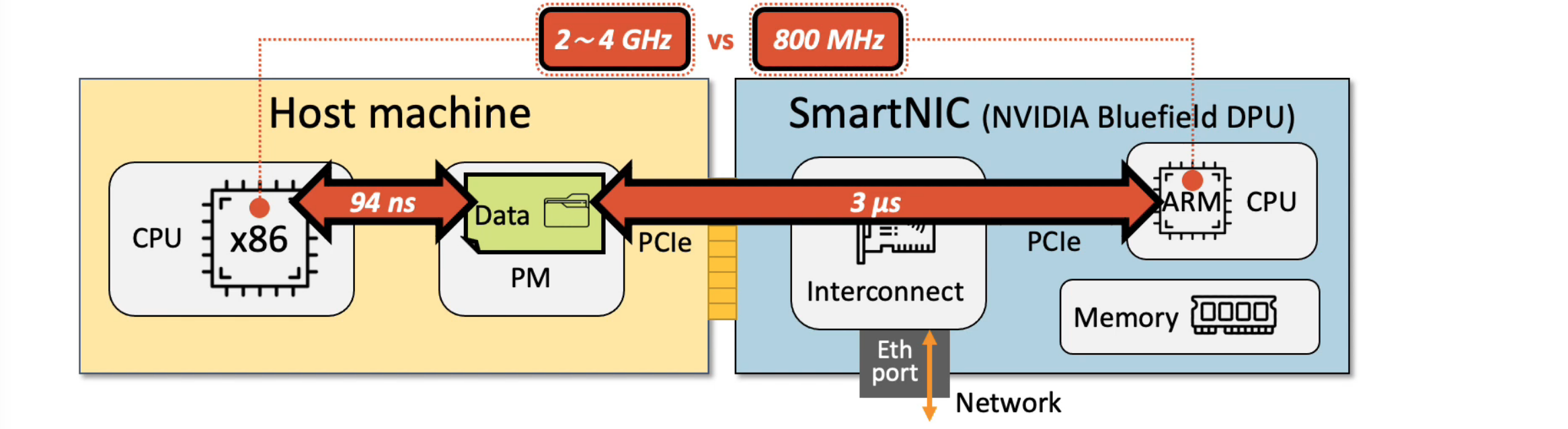
- 智能网卡中的ARM CPU访问PM,其需要经过PCIe总线,延迟比CPU直接访问大很多。
- 智能网卡中的ARM CPU性能一般较弱,其性能可能还不到主机CPU的1/3。
这两个挑战意味着简单的把DFS卸载下去,DFS的性能会很差。作者提出了 LineFS,其针对上面的两个挑战,分别进行了针对性的设计和优化:
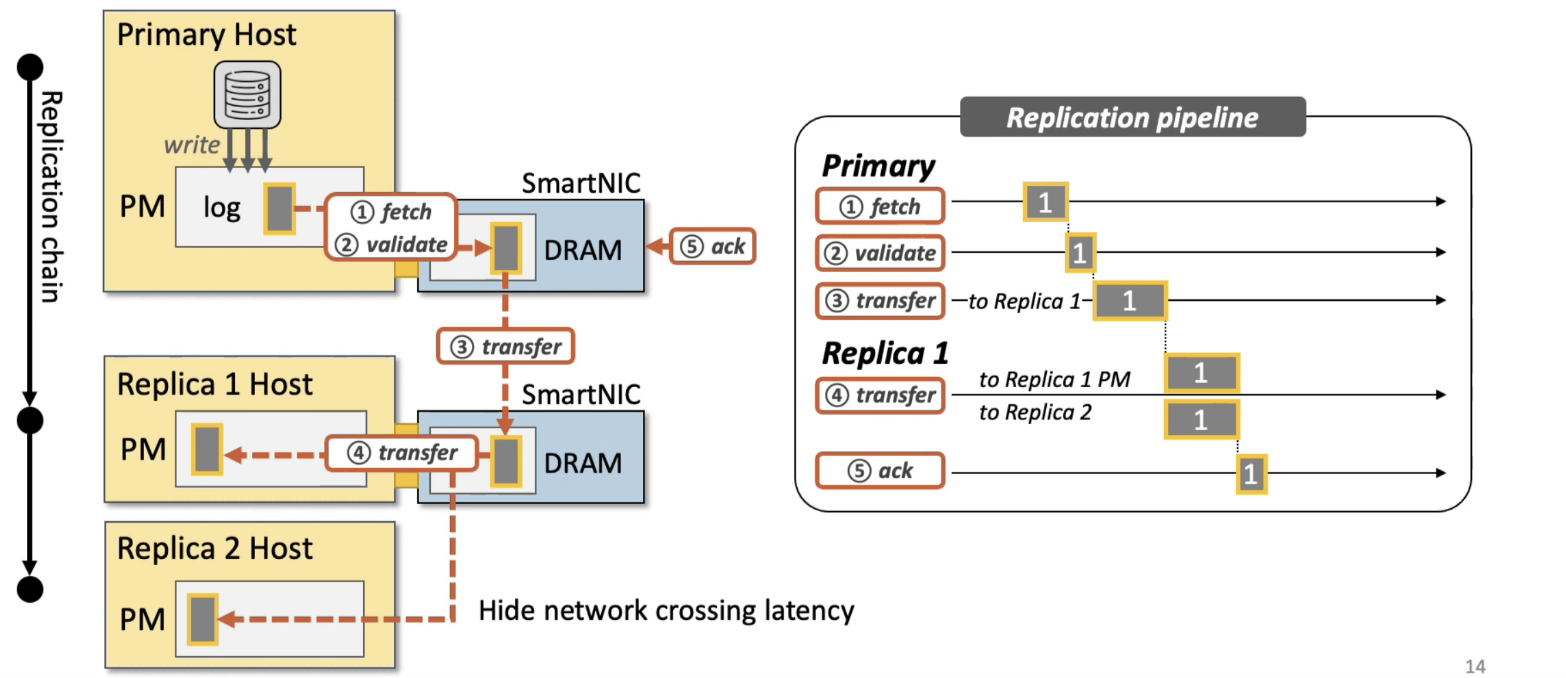
- 首先是写入模式的调整。LineFS采取了 Persist-and-publish
的写入模式,其含义是:对于写入操作,首先使用本地CPU持久写到本地的log中(Persist阶段,此时只在本地可见,但其他节点不可见),然后再使用SmartNIC中的ARM
CPU进行Publish操作。
- 从延迟来说,该实现保证了延迟。
- 【第一处流水线】从吞吐量来说,在Publish阶段将log中的多个操作批量处理,可以采用流水线的方式隐藏PCIe总线的延迟,提高吞吐量。
- 代价:文件操作的可见性受到了影响。

- 然后是为了保证高可用,LineFS还需要实现副本。
- LineFS将副本卸载到SmartNIC
- 为了提升副本的吞吐量,其采用了流水线的方式。
LineFS还将数据压缩等任务卸载到了 SmartNIC 中,在测试中,无论是纯DFS本身的性能,还是DFS和streamcluster同时执行,LineFS的性能都要比Assise好,资源干扰程度也比Assise少,另外,在LevelDB和FileBench的性能测试中,分别取得了80%和79%的提升。
Automated SmartNIC Offloading Insights for Network Functions
Yiming Qiu (Rice University), Jiarong Xing (Rice University), Kuo-Feng Hsu (Rice University), Qiao Kang (Rice University), Ming Liu (University of Wisconsin at Madison/VMware Research), Srinivas Narayana (Rutgers University), Ang Chen (Rice University)
Session 17: Storage
The Aurora Single Level Store Operating System
The Aurora Single Level Store Operating System
Emil Tsalapatis (University of Waterloo), Ryan Hancock (University of Waterloo), Tavian Barnes (University of Waterloo), Ali José Mashtizadeh (University of Waterloo)
现在的操作系统将易失的内存和持久的存储区分开来,使用两套完全不同的接口来使用,对于需要持久存储的应用(如数据库等),需要有大量的代码用于将内存中的数据进行格式转换并一致且持久地存储在持久存储设备上,而这部分代码也最容易产生bug。
能否让内存和持久存储看做一个整体呢?作者首先摆出了概念:Single Level Store,含义是操作系统能够提供持久服务,应用完全不需要关注持久化相关的细节。 具体来说,就是OS需要将应用的所有状态都持久存储起来,这样即便掉电后,该应用依然能够轻易的从中断点开始继续运行。这个概念并不是新的,但以前由于持久存储设备太慢,为了实现持久化应用所造成的额外开销太大,但现在随着存储设备以及传输总线不断升级,持久存储和内存之间的性能差距越来越小了。
Aurora 提供了两种方法持久化一个应用,一种方法是对应用透明的定期checkpoint(每10ms),这种方法实现的效果与criu类似,不过有着比该工具更低的开销。另一种方法是提供 Aurora API 供应用处理,用户可以通过这些API指定哪些对象要持久化,哪些不需要,从而减小checkpoint的开销,并且能够保证持久化的一致性。在实验效果中,运行在 定制的 Aurora API 下的 RocksDB,其能够提供和带WAL的RocksDB相当的持久性,而吞吐量能提高 75%。
WineFS: a hugepage-aware file system for persistent memory that ages gracefully
WineFS: a hugepage-aware file system for persistent memory that ages gracefully
Rohan Kadekodi (University of Texas at Austin), Saurabh Kadekodi (Carnegie Mellon University), Soujanya Ponnapalli (University of Texas at Austin), Harshad Shirwadkar (Google), Greg Ganger (Carnegie Mellon University), Aasheesh Kolli (Penn State University and VMware Research), Vijay Chidambaram (University of Texas at Austin and VMware Research)
这篇文章主要研究持久内存上的文件系统,更具体地说是在mmap场景下使用大页产生的问题。大页的使用是有必要的,因为使用大页能够大大减小大片PM空间中Page Fault的开销,同时也降低了 TLB Miss的情况。但大页的使用也带来了空间管理上的问题,若在文件系统的空间分配中,没有对齐大页的边界,则容易在文件系统老化后,内存页的内部碎片变得严重,进而导致性能下降。
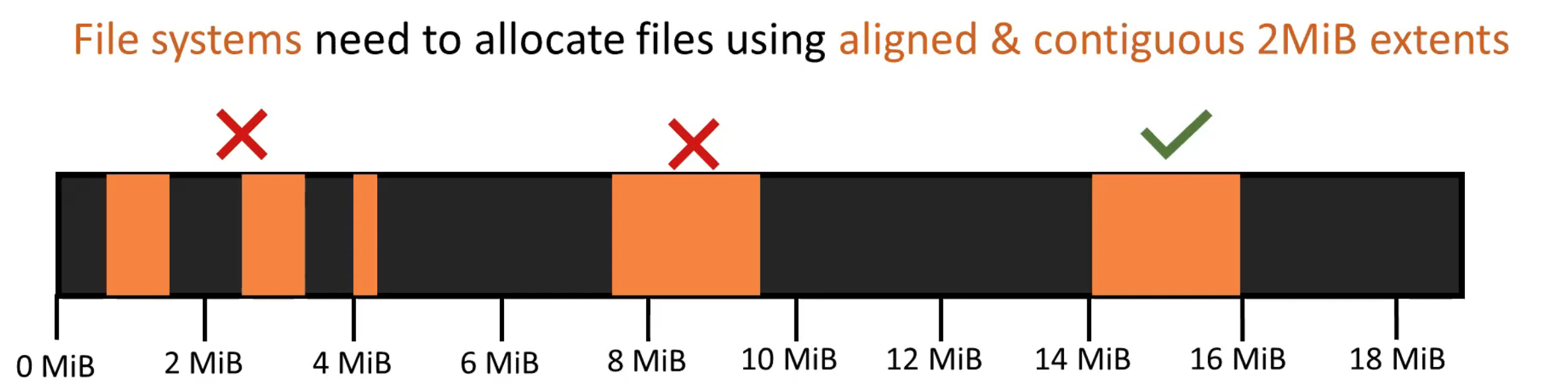
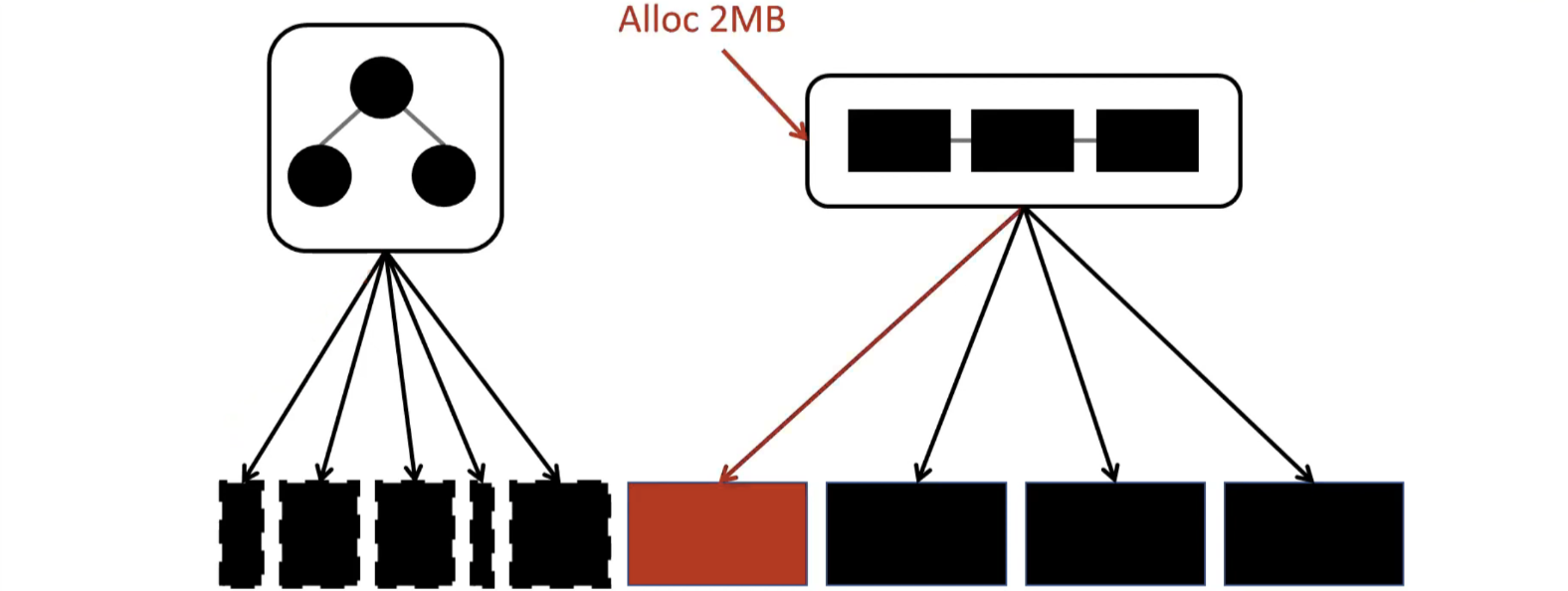
WineFS使用了一种大页感知的内存分配方法。具体地说,ext4-dax和xfs-dax其分配空间时,仅关注空间的连续性,但不关注空间对齐到2MB边界,而WineFS能够对齐到大页的边界。WineFS将分配分为两类,一类是小块的分配,这类分配则公用单个大页(或多个大页),且对齐到大页的边缘,对于大块的分配,则在对齐到大页边缘的同时在大页上连续存放。
Scale and Performance in a Filesystem Semi-Microkernel
Scale and Performance in a Filesystem Semi-Microkernel
Jing Liu (University of Wisconsin–Madison), Anthony Rebello (University of Wisconsin–Madison), Yifan Dai (University of Wisconsin–Madison), Chenhao Ye (University of Wisconsin–Madison), Sudarsun Kannan (Rutgers University), Andrea Arpaci-Dusseau (University of Wisconsin–Madison), Remzi Arpaci-Dusseau (University of Wisconsin–Madison)
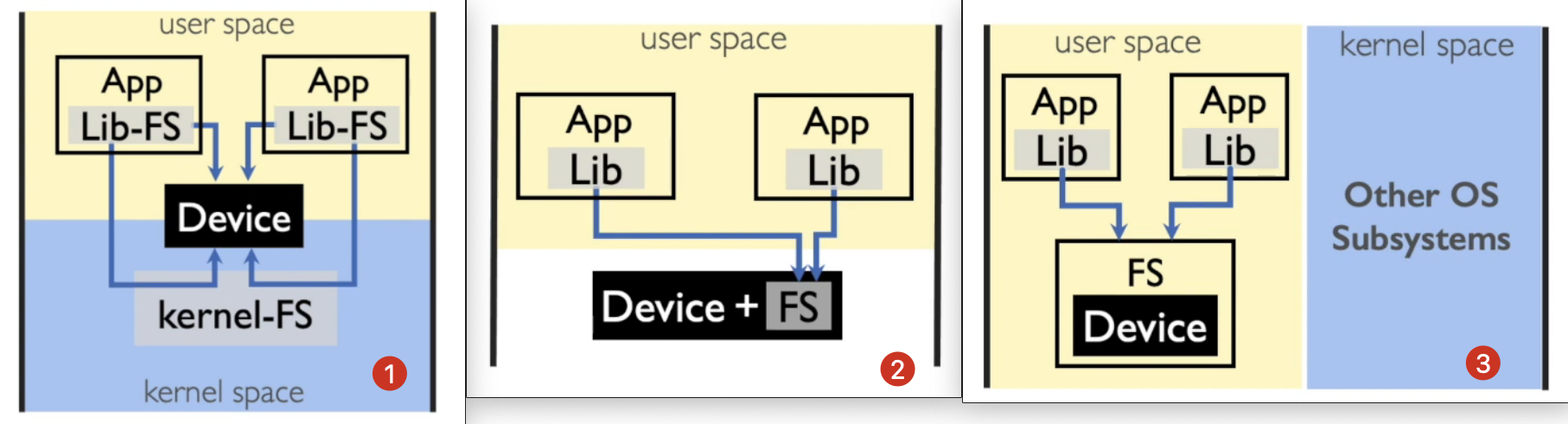
这篇文章的主要工作是在半微内核(Semi-Microkernel)上实现文件系统,其主要背景是如今存储设备性能越来越高,内核文件系统不可避免的会带来大量的软件开销,导致内核中的开销成为主要的瓶颈。为了解决这个问题,目前前沿的研究中主要有这两种方式来实现文件系统,(1)一种是以libfs的方式将整个fs作为一个lib链接到用户应用,让用户应用直接访问设备,(2)另外一种方式就是把整个fs放到设备中。但这两种方法各有优劣,前者难以实现存储设备跨应用的隔离和共享,后者对硬件要求高,需要假定存储设备上有一定的计算能力,但实际上大多数硬件并不满足该要求。作者提出使用(3)半微内核的方式,将一整个文件系统服务作为一个独立的用户进程,用户通过调用lib中的接口来和文件系统交互。
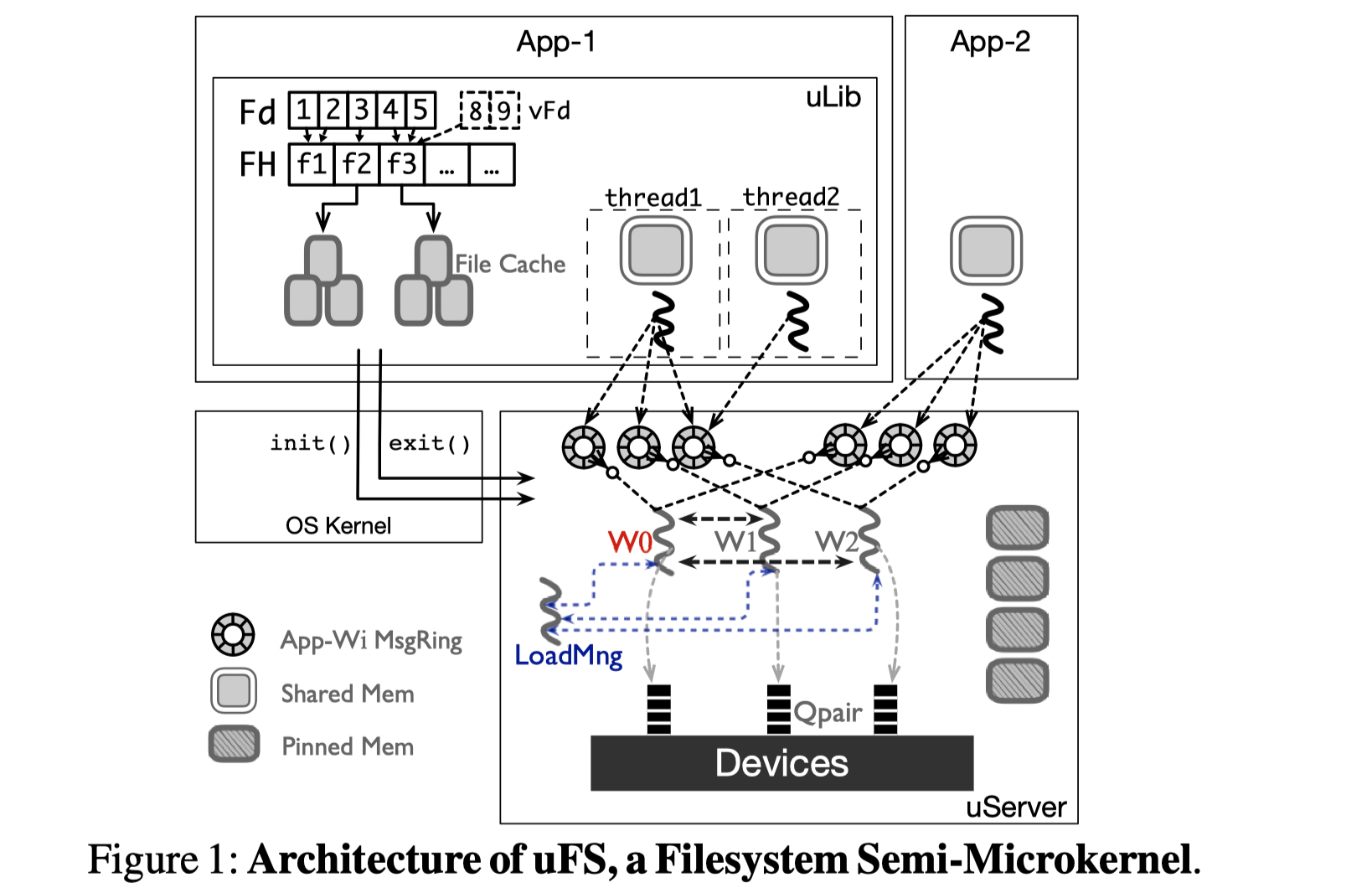
使用半微内核的方式实现文件系统需要解决的问题是:1)提高跨进程通信的性能。2)用户态进程对存储设备的高速访问。3)对动态负载的自动伸缩和适应。针对这几个挑战,作者提出了uFS架构,应用使用uLib调用文件系统相关操作,并由uServer来完成。对于第一个挑战,uFS使用无锁的ringbuffer来实现控制信号在uLib和uServer之间的传递,而数据内容则使用uLib和uServer之间共享的内存区域避免内存拷贝。对于第二个挑战,作者使用了spdk中最底层的接口spdk_nvme_ns_cmd_read
以及 spdk_nvme_ns_md_write
来实现(不算贡献),对于第三个挑战,作者一方面将INode灵活分配给单独的worker线程,实让worker线程之间的数据结构相互独立,无需同步(代价是一个文件的I/O只能由一个worker线程来完成),另一方面在
uServer 中实现多个可灵活扩缩的worker线程来实现并发处理I/O,同时实现
Inode 的灵活分配机制让多个worker线程的负载尽可能均衡来提高扩展性。
在实验中,作者将uFS原型与内核中自带的ext4进行比较,从数据操作到元数据操作进行了全面充分的测试,另外在LevelDB上运行YCSB基准测试,其性能能够达到ext4的两倍。
参考资料
Notes mentioning this note
There are no notes linking to this note.