The different stage of the pipeline execution for an instruction in CPU Microarchitecture
Updated: Oct 19th, 2023
Version 1
- fetch
- decode
- execute
- write-back
- write back to the register
 Modern
Microprocessors - A 90-Minute Guide!
Modern
Microprocessors - A 90-Minute Guide!
Version 2
- fetch
- decode
- execute
- Retire
- (for only store instruction) My understanding is that once the store is in the store buffer and it is non-speculative, the corresponding store uop is safe to deallocate the resource related to it in the ROB and make it visible in the core.
-
x86
- Committed Vs Retired instruction - Stack Overflow
- retirement occurs when the reorder buffer entries occupied by the instruction get deallcoated
-
What
does “Instruction Retired” mean exactly? - Intel Community
- CPU indeed speculatively executes much more instructions. But results are “stored” only for retired instructions.
-
Instructions
Retired Event
- Modern processors execute much more instructions that the program flow needs. This is called a speculative execution. Instructions that were “proven” as indeed needed by the program execution flow are “retired”.
- Commit
-
x86
- Committed Vs Retired instruction - Stack Overflow
- Memory stores have one additional stage called commit in which the store is actually performed. That’s because Intel processors have Store Buffer where stores can be marked as retired.
-
performance
- Size of store buffers on Intel hardware? What exactly is a store
buffer? - Stack Overflow
- The store buffer commits data from retired store instructions into L1d as fast as it can, in program order (to respect x86’s strongly-ordered memory model3). Requiring stores to commit as they retire would unnecessarily stall retirement for cache-miss stores. Retired stores still in the store buffer are definitely going to happen and can’t be rolled back, so they can actually hurt interrupt latency.
-
performance
- Size of store buffers on Intel hardware? What exactly is a store
buffer? - Stack Overflow
- The store buffer is used to track stores, in order, both before they retire and after they retire but before they commit to the L1 cache2.
- cpu - Out-of-order instruction execution: is commit order preserved? - Stack Overflow
-
x86
- Committed Vs Retired instruction - Stack Overflow

Modern Microprocessors - A 90-Minute Guide!
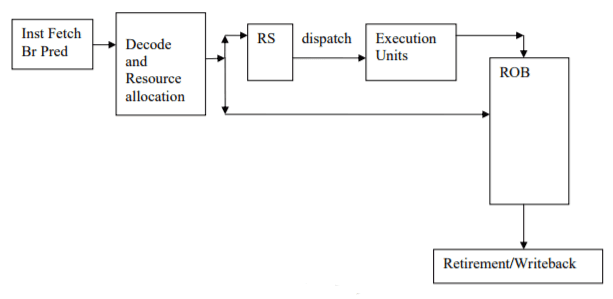
Version 3
- Fetch
- Fetches instructions each cycle, selecting which thread to fetch from based on the policy selected. This stage is where the DynInst is first created. Also handles branch prediction.
- Decode
- Decodes instructions each cycle. Also handles early resolution of PC-relative unconditional branches.
- Rename
- Renames instructions using a physical register file with a free list. Will stall if there are not enough registers to rename to, or if back-end resources have filled up. Also handles any serializing instructions at this point by stalling them in rename until the back-end drains.
- Issue/Execute/Writeback
- Our simulator model handles both execute and writeback when the execute() function is called on an instruction, so we have combined these three stages into one stage. This stage (IEW) handles dispatching instructions to the instruction queue, telling the instruction queue to issue instruction, and executing and writing back instructions.
- Commit
- Commits instructions each cycle, handling any faults that the instructions may have caused. Also handles redirecting the front-end in the case of a branch misprediction.
fetched (f), decoded (d), renamed (n), dispatched (p), issued (i), completed (c), and retired (r).
reference
There are some materials you should read:
- Modern Microprocessors - A 90-Minute Guide!
- gem5: Out of order CPU model
- Chapter 4 : Processor Architecture in Book[1]
- Instruction pipelining - Wikipedia
- Classic RISC pipeline - Wikipedia
- Superscalar processor - Wikipedia
- Chapter 3. Computer Architecture
- Software optimization resources. C++ and assembly. Windows, Linux, BSD, Mac OS X
[1]
R.
E. Bryant and D. O’Hallaron, Computer systems: a programmer’s
perspective, Third edition, global edition. Boston München: Pearson
Education, 2016.
Notes mentioning this note
There are no notes linking to this note.