The Performance of CXL Memory (Latency and Bandwidth)
Updated: Nov 15th, 2023
I collect some materials about the performance of CXL Memory.
Latency Assumption from Paper
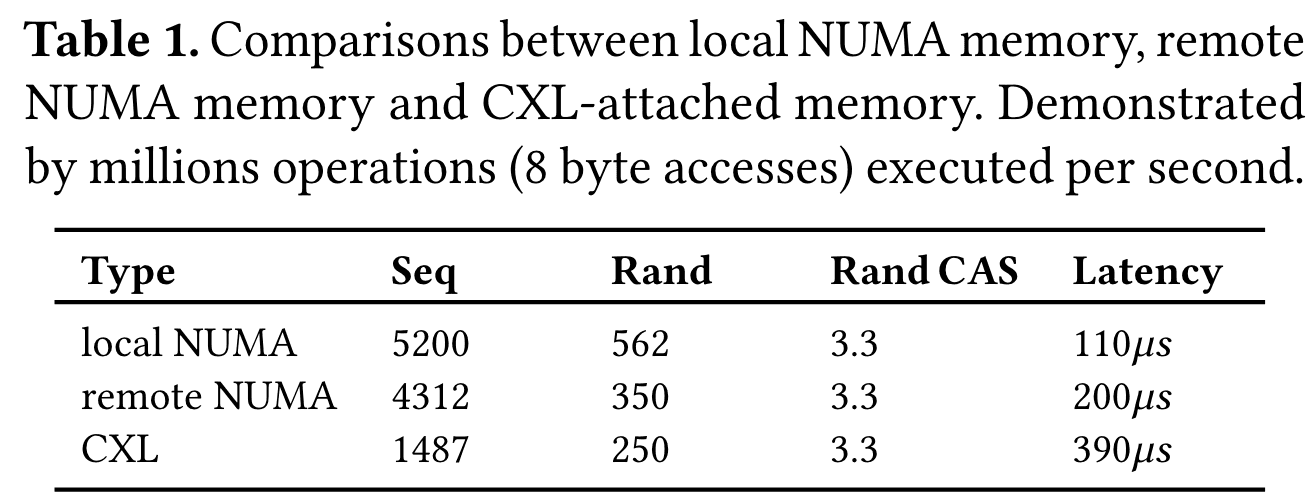
CXL-SHM[1]

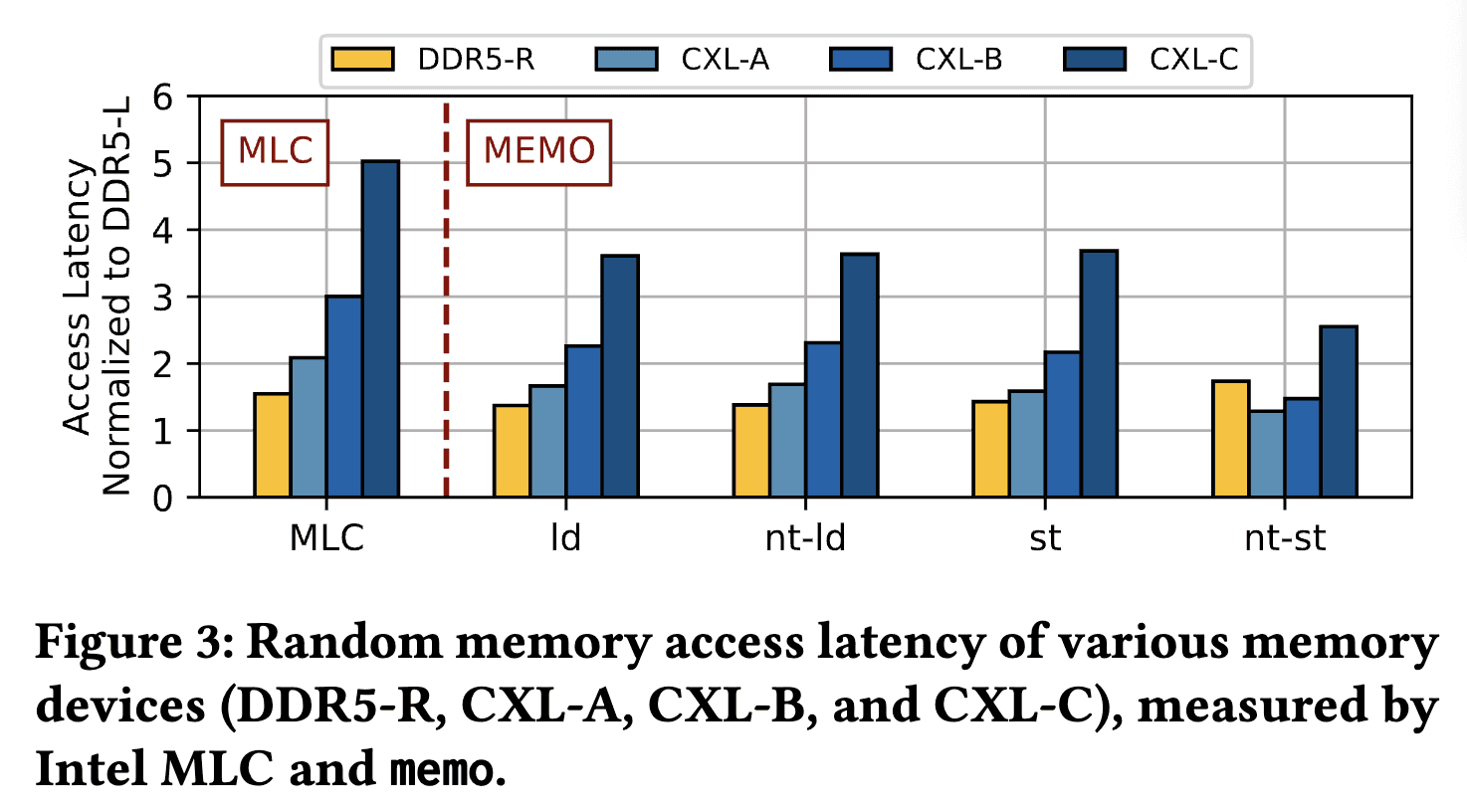
source: [2] Demystifying CXL Memory with Genuine CXL-Ready Systems and Devices
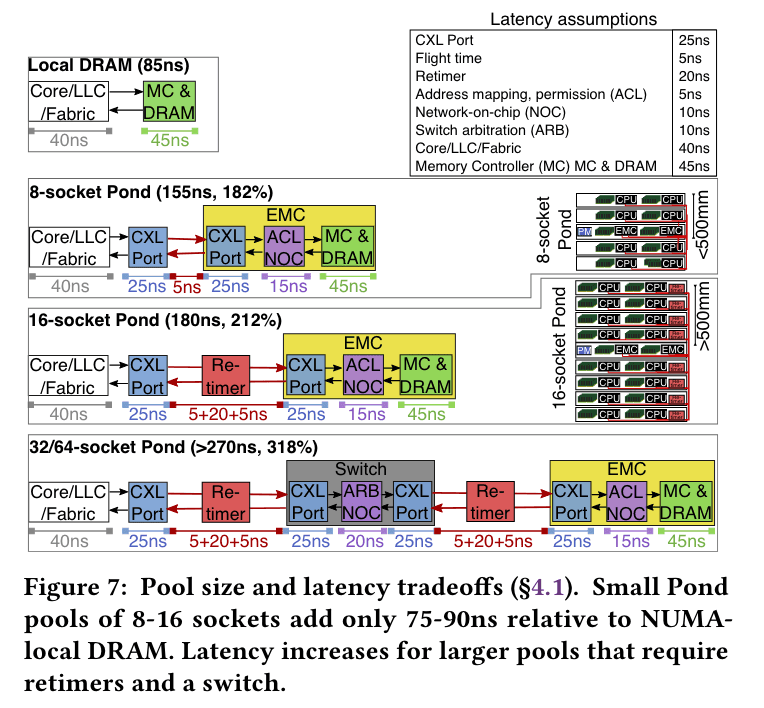
source: [3]

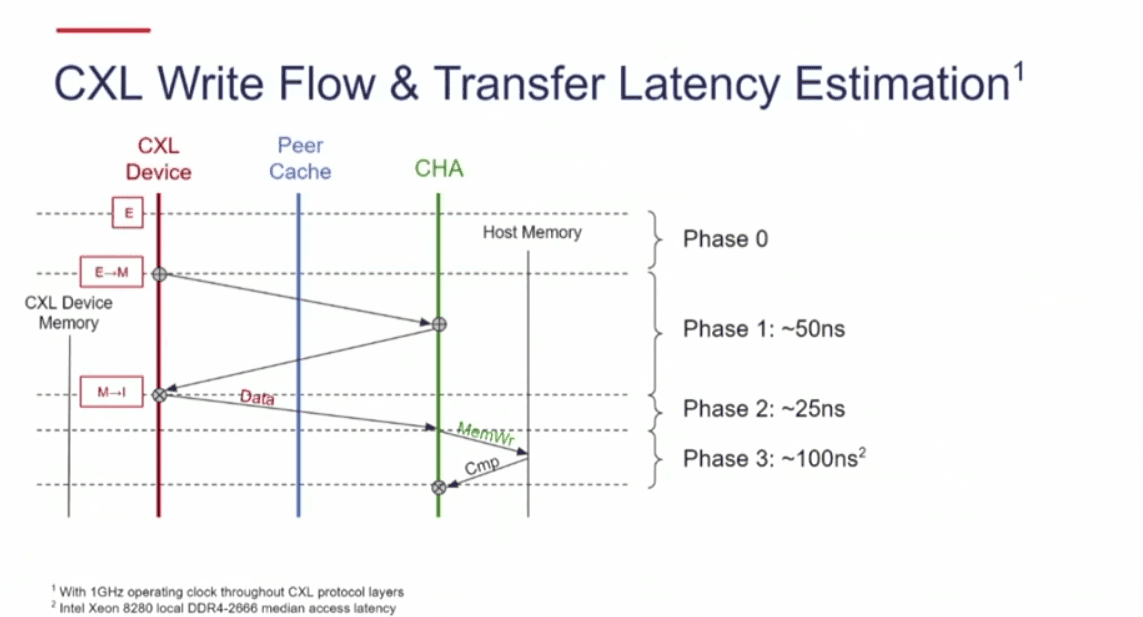
source:[4]
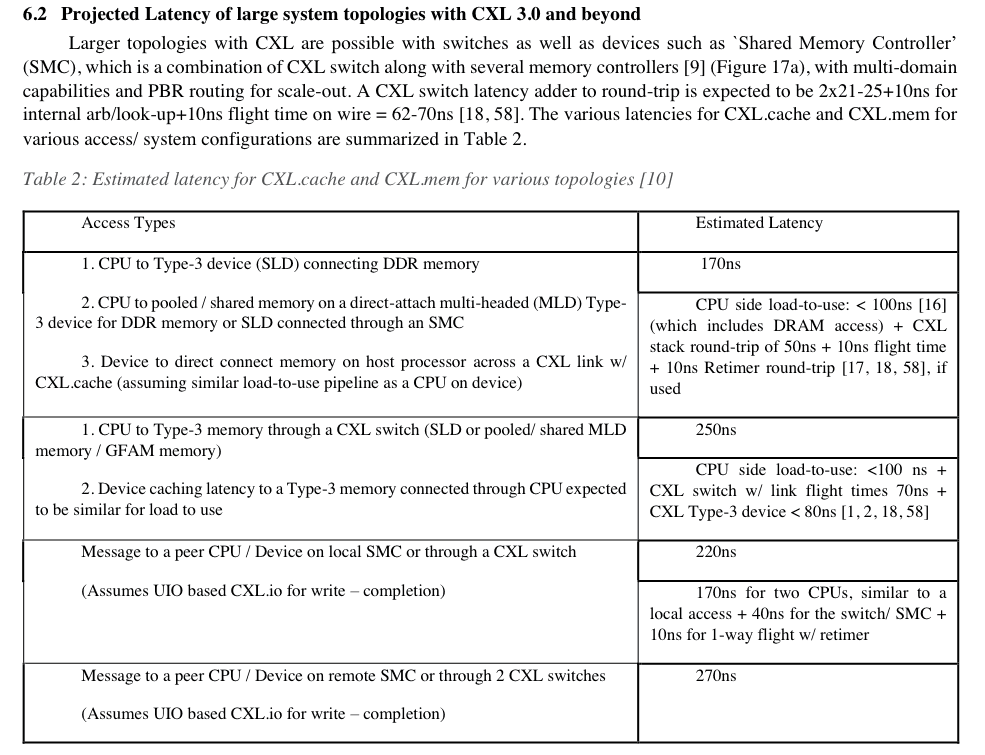
source:[5]
“The CXL 3.0 standard sets an 80ns pin-to-pin load latency target for a CXL-attached memory device [9, Table 13-2], which in turn implies that the interface-added latency over DRAM access in upcoming CXL memory devices should be about 30ns. Early implementations of the CXL 2.0 standard demonstrated a 25ns latency overhead per direction [42], and in 2021 PLDA announced a commercially available CXL 2.0 controller that only adds 12ns per direction [43]. Such low latency overheads are attainable with the simplest CXL type-3 devices that are not multiplexed across multiple hosts and do not need to initiate any coherence transactions. Our key insight is that a memory access latency penalty in the order of 30ns often pales in comparison to queuing delays at the memory controller that are common in server systems, and such queuing delays can be curtailed by CXL’s considerable bandwidth boost.” (Cho et al., 2023, p. 3) (pdf) [6]
“Our results (Figure 2) show CXL memory access latency is about 2.2× higher than the 8-channel local-socket-DDR5” (Sun et al., 2023, p. 3) (pdf) [2]
Latency Assumption from CXL Specification
In “12.0 Performance Considerations” from the CXL Specification(pdf)[7]
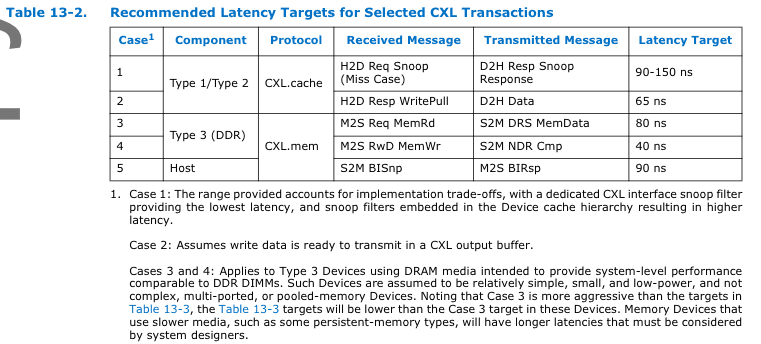
“At the Link Layer, the following maximum loaded latencies are
recommended. If not adhered to, the link between two ports risks being
throttled to less than the line rate. These recommendations apply to all
CXL ports and both the CXL.cache and CXL.mem interfaces. The targets
assume a x16 link with IDE disabled.” (Intel, 2022, p. 714)
(pdf)
[7]

“The total latency from the SERDES pin to the internal IP interface such as CPI (equivalent) and back is 21 ns in common clock mode and 25 ns in non-common clock mode. One IP vendor has reported their expected latency of 25 ns [8], presumably in the common clock mode. Some variations in this number is expected due to factors such as RC delays inside the chip depending on the placement of the various blocks, the process technology capability, and the type of PHY people design (for example, an ADC-based PHY would likely have an additional latency of around 5 ns over a DFE/ CTLE based Receiver design). However, these measured numbers give us confidence in the maximum pinto-pin round-trip latency targets of 80 nsec for a memory access for a Type-3 device with DRAM/ HBM memory or a 50 nsec snoop-miss response for a snoop.” (Sharma, 2022, p. 10) (pdf)
“With a 21/ 25 nsec round-trip latency, even after allowing an additional 10ns for variation due to different design practices, a very conservative 10 nsec flight time plus Flit accumulation latency for round-trip, we expect a latency adder of 70 nsec (2x25 + 10 + 10) for a memory access across CXL Link, whether it is a CPU accessing a CXL device attached memory or a CXL device accessing the CPU-attached memory. This is in line with what one would expect for an access across a CPU-CPU coherent link and well within the latency operating points of the latest reported Xeon CPU [15]. A load to use latency for coherent access across CXL Link is expected to be significantly less than 200 nsec, not accounting for queuing delay [16]. This is consistent with the 150 and 175 nsec projection for different types of accesses by an IP vendor [8]” (Sharma, 2022, p. 10) (pdf) [8]
Other Information
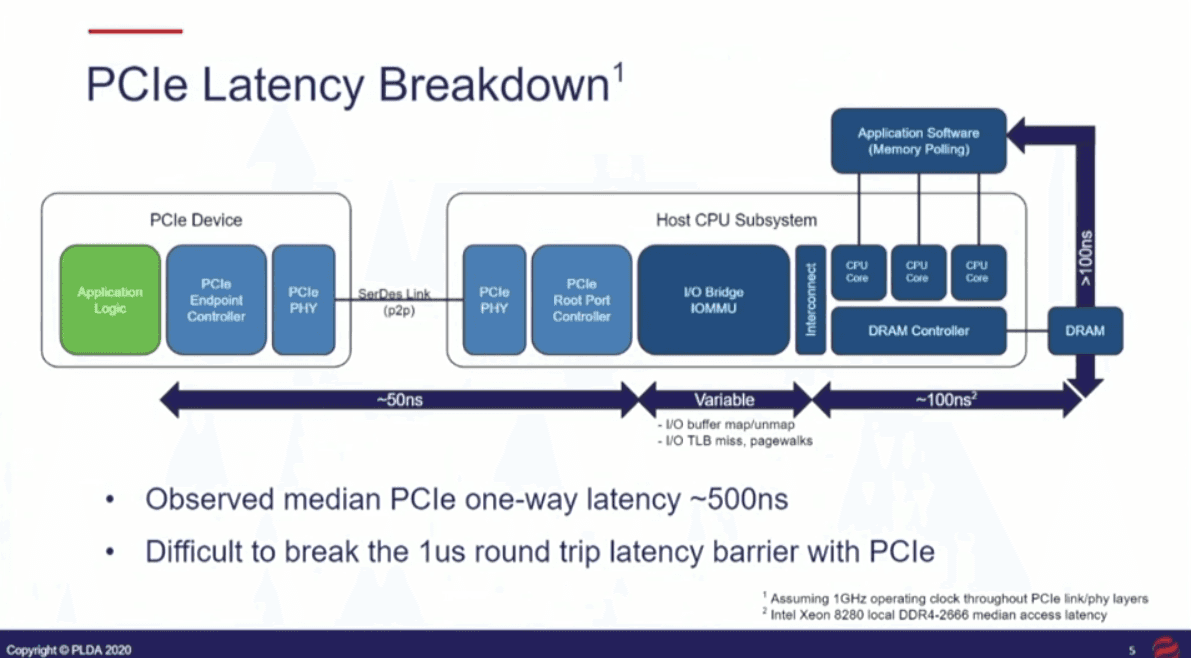
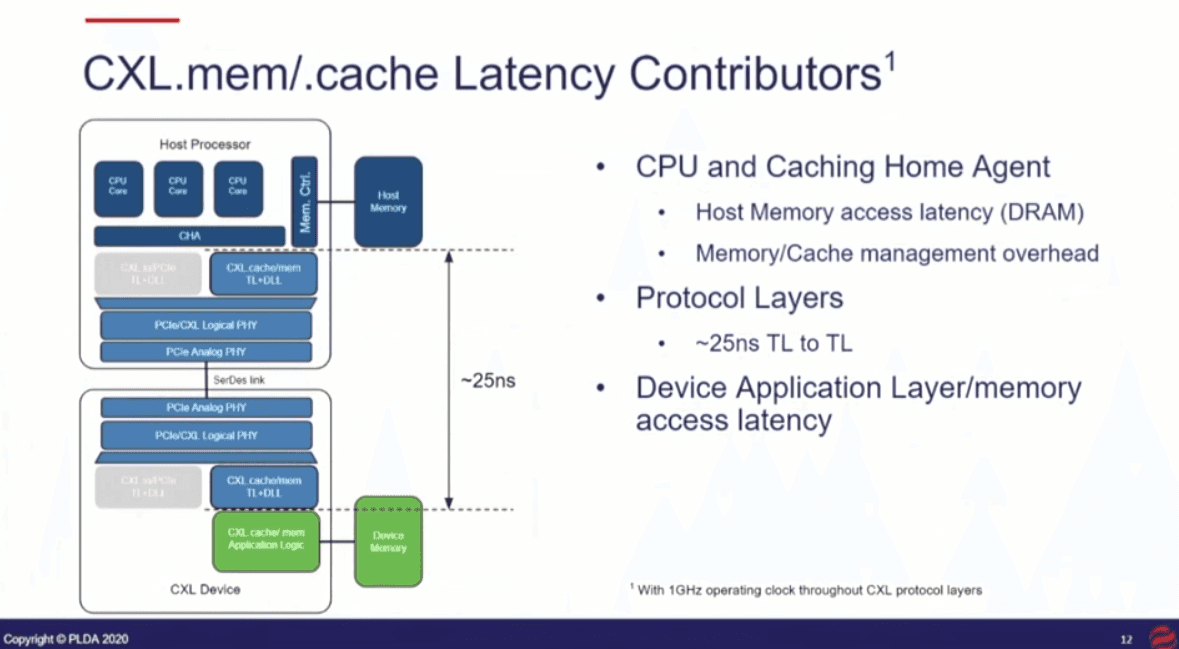
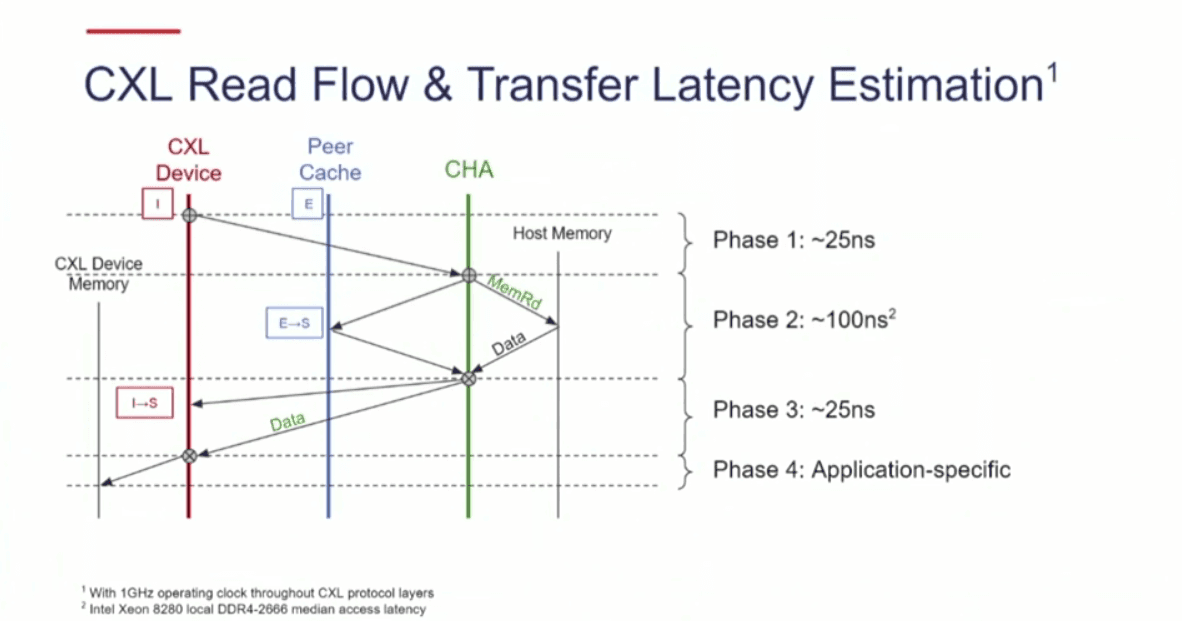
Breaking the PCIe Latency Barrier with CXL
Notes mentioning this note
There are no notes linking to this note.