Ext2 File System
Updated: Sep 21st, 2023
文件系统存在的意义,便是将对物理磁盘上具体盘片、柱面、扇区、磁道等资源的管理,抽象成“文件”,便于用户进行处理。我希望,通过对ext2文件系统的分析,我能够将这一层抽象一层层打开,在我们使用命令行上瘾一般地ls、cat等操作时,我们还能够回答这样的问题:当我在处理文件的时候,文件系统究竟在干什么?这篇文章看下来,我希望你也能够这样感叹:“我也会自己写一个文件系统了”。
1. 物理磁盘的抽象-块设备
在实际的实现中,盘片、柱面、扇区、磁道这些概念已经被Linux内核中的通用块层、块设备驱动程序等中间层屏蔽了,无数种磁盘,最终都被抽象成为“块设备”。块设备是一种将数据块按照线性排列的一种存储设备,数据块的大小一般在1KB(1024bytes)、2KB、4KB等等。通过这种抽象,我们只需要一个线性的索引值,便可以直接读写物理磁盘上的某个数据块。
后面我们讲的文件系统,便是在块设备这个层级上,将“文件”与块设备上的“块”关联起来。一般来说,将物理磁盘使用数据块划分开来,是“格式化”工作的一部分,块的大小一旦被定好之后,除非重新格式化,否则不再改变。现在一种比较通用的做法是,将块的大小作为文件系统的一个参数。
2. 文件的表示
文件,抽象来说就是一段连续的比特序列,这样的比特序列在物理磁盘中可以有多种方式存储,这里我就仅对ext2文件系统的做法进行说明。
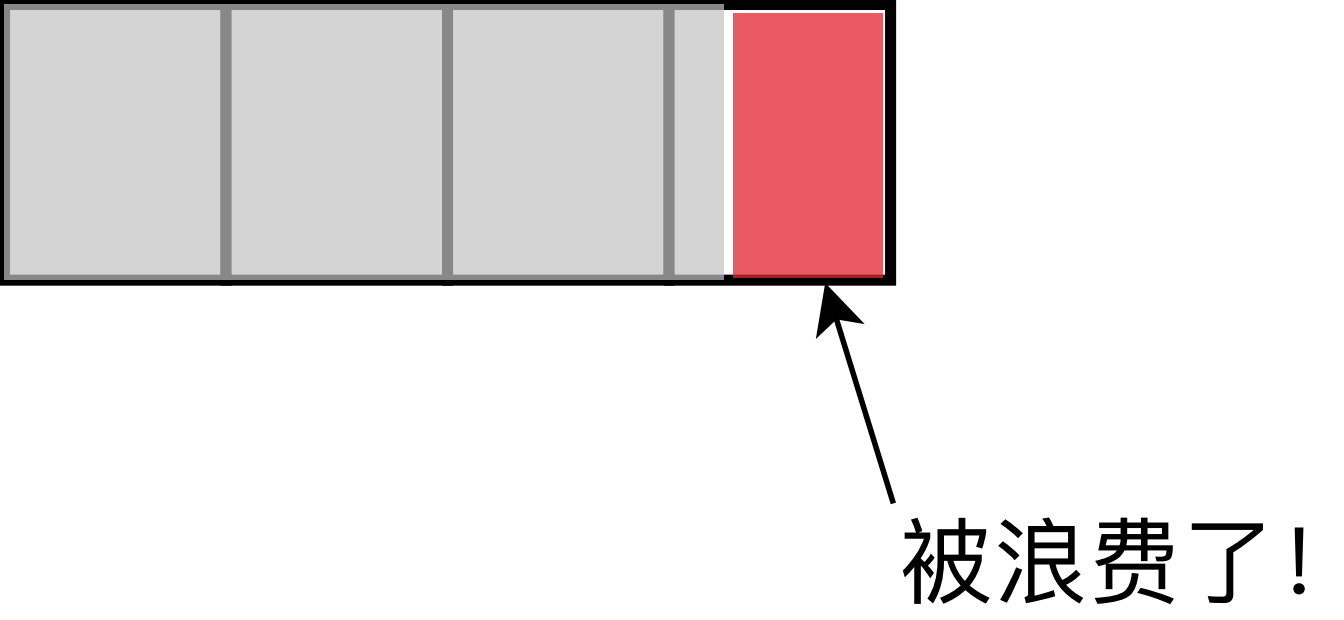
首先,一个文件会使用数据块进行表示和存储。 这是什么意思呢?比如我现在有一个数据块为4KB的ext2文件系统,那么一个小于4KB的文件,我们就会使用一个数据块进行存储即可,而大于4KB的文件,比如7KB,我们就需要两个数据块进行存储。更大的文件以此类推。需要注意的是,目前的实现中,由于对数据块进行了抽象,因此一个数据块仅能属于一个文件,这意味着如果单个文件用不满一个数据块,数据块中剩余的空白将永远无法被利用。这就是数据块可能会导致的一种“碎片化”现象。如果在数据块为4KB的文件系统上存放了多个大小仅1KB的文件,每个文件就会导致3KB的空间被浪费!因此,数据块大小的设置,与文件系统上存放的文件平均大小息息相关,这个参数的设置也会对文件系统的各项性能有较大的影响,需要加以重视。
3-inode数据结构的进一步讲解
前面说到过,一个文件对应一个inode,能够理解inode数据结构,就在理解ext2文件系统的道路上走了一大步了!
ext2文件系统上的inode,包含了权限、拥有者、修改时间、数据块索引这四大类信息,按照实际的数据编排可以进行如下介绍。
- mode
- 这个inode描述的东西是什么?由于inode既可以表示一个文件,还可以表示目录、链接、设备等,因此需要区分。
- 权限,这一项同时还记录了访问这个inode的权限信息。
- owner informance
- 表示该inode拥有者的标识符
- timestamps
- 表示该inode最后一次被修改的时间
- datablocks
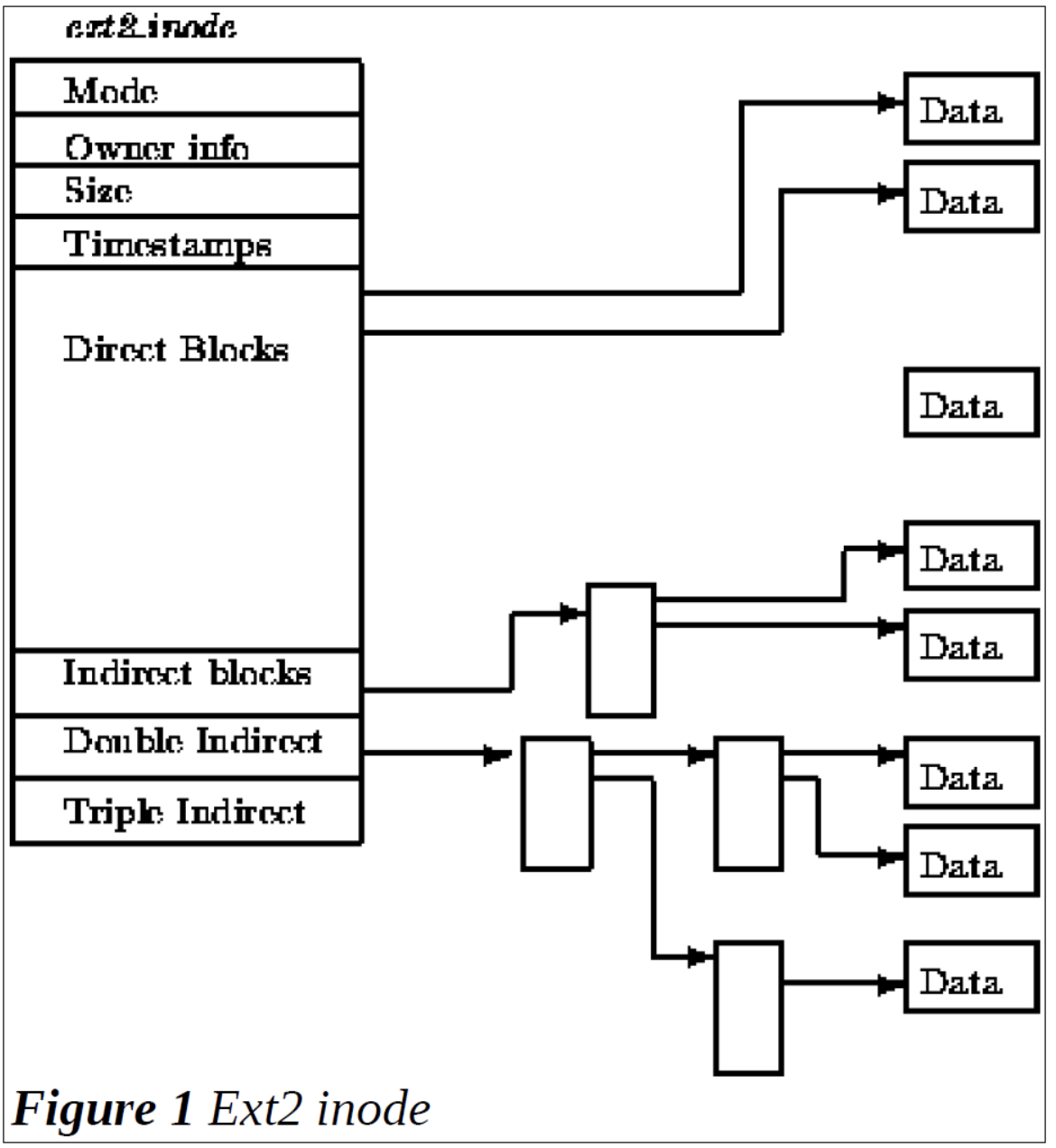
- 存放了该inode表示的文件对应的数据块的索引值,其中存放了15个索引值(固定)。
暂时还不会讲解到源码级别,因此知道inode有以上信息就足够了,不过我们需要知道一点:一个inode的大小是有固定的,在ext2文件系统中,inode的大小固定为128bytes。因此在上面datablocks一项中,仅仅固定存储15个索引值,但是,如果所需要表示的文件,大于15个数据块能表示的范围呢?这就是一个巧妙的地方了:
inode存放的15个地址里,前面12个是直接索引值,也就是说,前面12个索引值指向的就是文件的数据块,这12个索引值,能够表示12*4KB=48KB大小的文件。
第13个索引值,存放的是一级间接索引值,这个索引值指向的数据块,存储的并不是文件的内容,而是直接索引值!4KB的数据块,一个索引值需要4byte来存储(一个int32),因此能够存储1K个数据块的索引值,对应4MB的文件大小。
第14个索引值,存放的是二级间接索引值,二级间接的含义是,这个索引值指向的数据块,该数据块包含的内容都是一级间接索引值,通过二级间接索引值,能够表示4BG的文件大小。
以此类推,第15个索引值,便能够表示4TB的文件大小,由于ext2中固定了inode的表示,其中仅含有这15个索引值,因此ext2文件系统中能够存放的文件大小最大也就 4TB+4GB+4MB+48KB。文件大小是有上限的!
为了更好的理解ext2中的inode,下面放了一个图形表示。
这里放一个更加细致的图
! [[ Pasted image 20220530132229.png ]]
4-块设备内容组织
目前应该对单个文件的存储比较清楚了,文件分块存储,索引值以及相关属性存储在inode上。现在来解决下一个问题:文件数据块是直接放在块设备上的,放在哪里呢?inode是如何存放在块设备上的呢?在这一节,我希望能够对块设备上的内容组织,做一个较为全面的阐述。
再次强调一遍,块设备是物理磁盘的一种抽象,在块设备上数据块线性排列,以0开头的全局索引值能够直接索引到块设备上的任意一个数据块。在这样的前提下,ext2文件系统又对这些数据块进行了一个分组,每个分组称为一个块组(block group)。如下图所示,除去第一个块作为“引导块 (boot block)”之外,剩余的所有块会被划分成为一个一个块组。
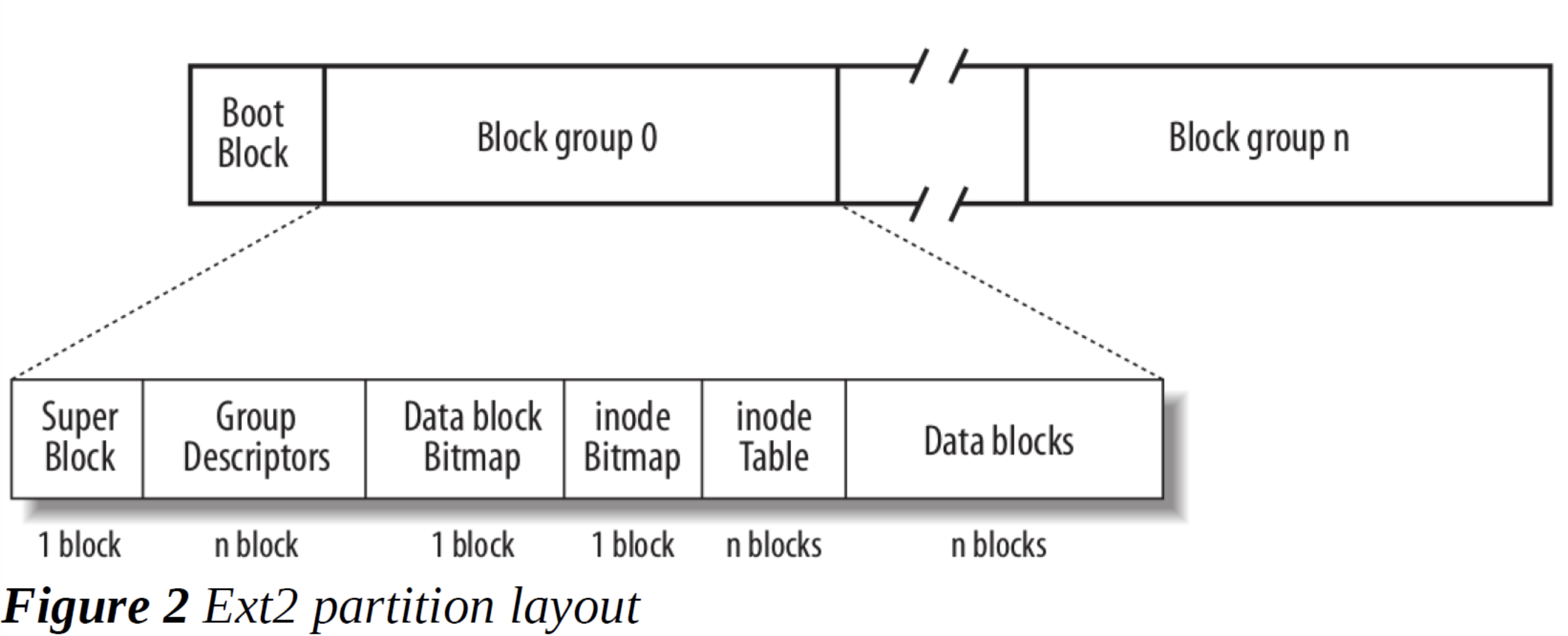
块组0中,会包含如下的内容:
| 名字 | 数据块个数 | 作用 |
|---|---|---|
| 超级块(Super Block) | 1 | 描述了ext2文件系统的各项参数,如数据块大小,就会写在这里。 |
| 组描述符(Group Descriptors) | n | 存有块组中数据块位图、inode位图、inode表的索引值 |
每个块组一定都包含以下内容:
| 数据块位图(Data block Bitmap) | 1 | 使用位图表示数据块的空闲情况,一个bit表示一个数据块。 |
|---|---|---|
| inode位图(inode Bitmap) | 1 | 使用位图表示inode的空闲情况,一个bit表示一个inode。 |
| inode表(inode Table) | n | 按顺序存放一个一个inode |
| 数据块(Data blocks) | n | 按顺序存放一个一个数据块 |
通过以上内容,我们就可以得到以下事实:
- 数据块位图固定大小为一个块,因此一个块组中含有的数据块的数量也是固定的:4KB*8bit/bytes=2^15=32K
- 所有数据块总大小为 32K*4KB = 128MB
- inode位图的大小也是固定1个块,因此inode表所含有的inode数量也是固定的:4KB*8bit/bytes= 2^15=32K,所以inode表的大小也是固定的。
- 由于inode表和数据块的大小都固定了,因此整个块组的大小也是固定的,具体的值就不再去算了。
可能读者会有疑问,这个块组能够表示的文件太小了吧。
ext2是上个世纪就存在的文件系统,当时的文件确实没那么大,所以这也是合情合理的。
5-目录的表示
渐渐要进入文件系统的核心了,在更进一步阐述的时候,先弄清楚ext2文件系统是如何表示目录的。
Linux的核心哲学是“一切皆文件”,因此目录也是一个文件,目录也有对应的inode,我们接下来,便要对目录这一种特殊文件其中所含有的字段进行解析。
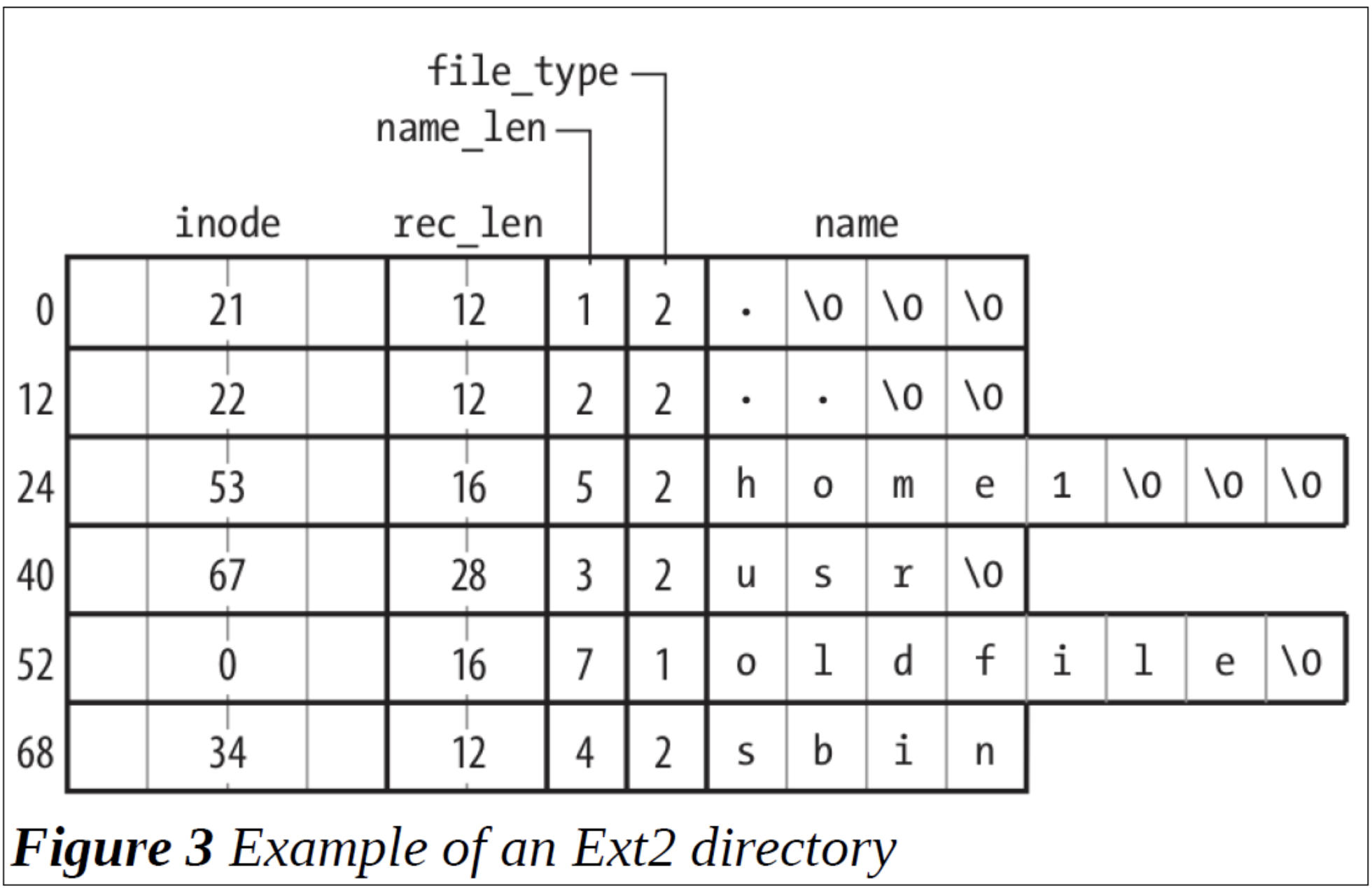
ext2文件系统中的目录文件,是一个列表,列表中存储了该目录下所有目录/文件的inode号、文件名等信息。这个列表中的每一项,其具体的含义是:
inode(4 bytes):该项文件对应的inode号。通过这一项,便能够所引导该文件对应的inode进而读取该文件。
rec_len(2 bytes):该项的长度,该项的开始地址+rec_len = 下一项的开始地址。这是为了支持可变文件名而做的一种设计。
name_len(1byte):文件名的长度,最长256就是这样来的。
file_type(1 byte):这个代表了这个文件的类型,目录/文件/链接/块设备/字符设备/套接字/未知等等
name(不定,通常是4的倍数):文件名,为了保证性能通常是4的倍数,如果不足会在后面加\0补足。
6-ext2文件系统需求、设计与实现
前面的内容,主要就文件、目录、inode等关键要素在磁盘上的具体方式以及内部的数据项进行了详细的讲解,在这里我们先来整理文件系统需要实现的需求(即API),然后再尝试讲解每一个需求的实现。
文件系统需要支持以下需求,功能方才较为完整:
- 从0在空白磁盘上创建一个ext2文件系统
- 根据路径寻找指定文件,并读取文件内容
- 写文件并改变文件内容
- 在内存中组织元数据以便减少磁盘读取次数,提高处理效率。
根据前面描述的ext2文件系统规范,对这些需求的实现进行讲解,才能够了解到ext2文件系统的全貌。希望读者在读完这一部分之后,能够有一种“我也能自己写一个ext2文件系统”的信心。
本来想结合Linux源码进行分析的,但是Linux上有一个vfs,将ext2文件系统的元数据读取出来组成vfs之后,就直接在vfs上操作了,不必受限于ext2文件系统,因此不便直接拿linux源码讲解。也许之后有必要的话,可以直接对vfs的源码进行讲解。
6-1-从空白磁盘上创建一个ext2文件系统
这一步,也就是俗称的“格式化”磁盘了,没错,我们就来尝试手动将一个空白磁盘格式化成ext2文件系统。如果不加设定,一般情况下ext2会有这几个默认参数:
- 数据块大小:1KB(我打算设为4KB)
- 检测坏块
- 保留块的百分比:5%,留下5的块备用
具体步骤如下
- 初始化超级块和组描述符
- 在格式化程序中设置的文件系统相关参数(如数据块大小)会被写入到超级块中。
- 由于块组的大小已经能够通过数据块大小确定,因此每一个块组的开始索引值以及内部每一项的开始索引值都能够完全确定。
- 遍历每个块组:
- 初始化inote位图(inode bitmap)为0、数据块位图(data bitmap)为0
- 初始化inode表
- 创建root文件夹,创建在第一个块组中的数据块中的第一个块。
- 创建lost+found文件夹,创建在第一个块组中的数据块中的第二个块,同时保留之后的10个块。
- 创建了两个文件夹,因此在inode位图和数据块位图中更新这两个文件夹对应的bit。
- 将坏块列表存到lost+found文件夹中。
如果对一个1.44MB的软盘进行格式化,那么最终的结果如下:

6-2 在ext2文件系统中定位一个文件
ext2文件系统中,文件名的组织方式和现在没有区别,下面以寻找“/home/wyf/myfile”文件为例。目标是找到这个文件的inode,从而读取文件内容。
首先读取根路径,根路径的inode是固定的inode 2,读取inode 2中的数据块索引,得到根路径的目录项。
根路径目录项中每一项存有该目录下每个文件的inode号、文件名等。遍历文件名,找到其中文件名等于“home”的一项,并读取得到/home对应的inode号。
读取的到了/home的inode号之后,就可以进一步读取/home的目录项了,使用相同的逻辑,寻找到其中/home/wyf的目录项,得到该目录的inode号。
根据/home/wyf的inode号继续读取该目录的目录项,在其中找到myfile,读取对应的inode号,然后就可以读取得到文件内容啦!
6-3 改变ext2文件系统中一个文件的大小
比如说有这样的一个场景:往后写入一个现有的文件,导致该文件大小变大,文件系统需要分配一个或多个数据块。为了进一步提高数据的空间局部性,文件系统一般会在现有的块临近的空闲块中寻找并分配,或者至少会在同一个块组中分配空闲块,实在没办法了,才会在其他块组中分配空闲块(这就是块组的意义!)。
ext2文件系统中的空闲块分配逻辑如下:
- 锁住超级块,不允许其他进程修改。
- 在分配、回收数据块的时候,需要修改超级块的一些项,linux最多仅允许一个进程进行这种操作。
- 超级块中有一项“空闲块数量”,如果数量足够,则继续分配,否则分配失败,结束,解锁超级块。
- 继续分配时,会尝试查看有没有预分配的块
- 如果有预分配的块,则使用预分配的,结束
- 没有预分配的块,必须新分配一个:
- 寻找这个文件最后一个块近邻着的下一个块,如果这一个块没有被使用,则分配这个块。
- 如果使用了, 那再往后找64个块,如果能找到空闲的,也可以。
- 如果还找不到,那就在块组中,寻找8个连续的空闲数据块,如果在块组中找不到那就在其他块组中找。
- 找到了之后,如果需要,更新一下预分配的相关参数和变量。
- 找到了空闲块之后,更新块组中的数据块位图,并更新超级块,如果这些数据暂时都存在内存中的时候,就都标记为dirty。
- 解锁超级块。
6-4 元数据在内存中的组织
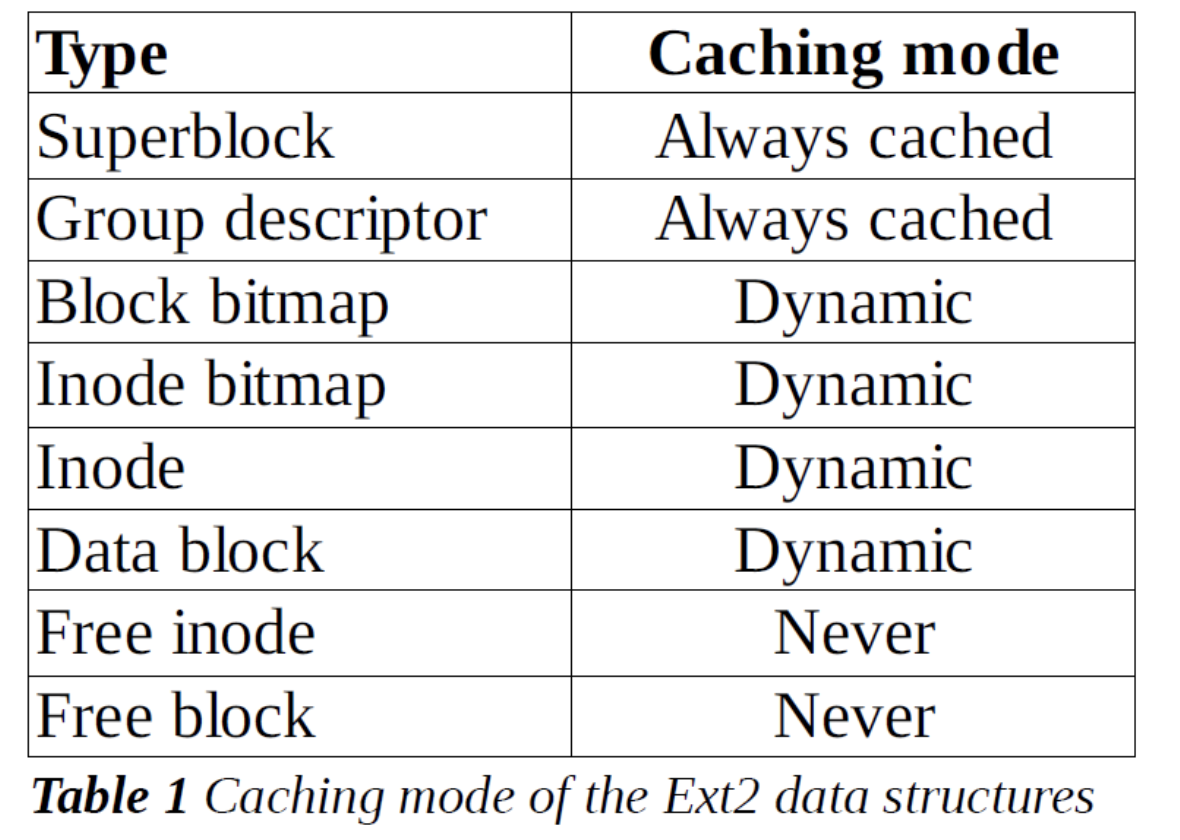
实际上,无论是超级块、inode、还是目录项, 这些常常需要被访问的内容如果仅存在硬盘上的话,这意味着每次我进行ls操作,都要进行多次数十毫秒的磁盘访问行为(读取超级块-root的inode-root的目录项-等等…),这显然是不合理的,在实际实现的时候,文件系统的这些数据,或者说,“元数据”,往往会缓存在内存上,仅在需要的时候读取磁盘,一般情况下, 读取内存就够啦。下表就是这些元数据在内存中的缓存情况。
7-小结
ext2文件系统还是一个十分简单的文件系统,ext3在ext2的基础上又增加了日志功能,在了解了ext2的构造细节之后,我想再去掌握ext3应该就很容易了。
参考资料
- 本文相当一部分内容来自📎The Ext2 File System.pdf 的整理。
- https://www.ibm.com/developerworks/cn/linux/filesystem/ext2/index.html
- Linux内核自带的文档:ext2.txt
- 《Understanding Linux Kernel》Chapter 18
- http://e2fsprogs.sourceforge.net/ext2intro.html
- https://zhuanlan.zhihu.com/p/53027856