Log-structured File System
Updated: Sep 21st, 2023
写一个很经典的文件系统:LFS(Log-structured File System)[1],该系统首次在1991年的SOSP 中提出。虽然来自很久远的文章,这个Log-structured的思想到现在依然不过时,在SSD以及PM中都时常被提起,特别是在Log-Structured Merge-Trees中。
动机:为什么要实现LFS
提出一个新系统,其最重要的目的是要解决问题,而LFS的提出,其想要解决的最大问题是:文件系统的写入速度很慢,根本吃不满当时磁盘的顺序写带宽。为了解决这个问题,当时的背景是怎样的呢?
- 机械硬盘的机械结构决定了其顺序写入的带宽一定远远大于随机读写的带宽。顺序读写时只需要维持磁盘旋转即可,而随机读写时,一旦目标磁道变了,每次读写就都需要一次耗时10ms左右的寻道。每次随机读写带来的额外寻道时间,对随机读写的性能造成了极大影响。
- 当时的文件系统,一个简单的操作需要通过多个随机读写请求才能完成。这导致操作文件系统过程里会产生大量的随机读写。这里举一个例子,如Ext2 File System,在一个文件夹中创建一个文件,需要 1)写入文件数据块到数据区域 2)修改数据块的bitmap,表示新占用了的数据块 3)创建新inode,在inode区域写入该文件本身的inode信息 4)修改inode bitmap,表示新占用了一个inode 5)修改文件所在文件夹对应数据块,在目录表中增加一项,可能也会涉及到新加数据块修改数据块bitmap 6)修改文件所在文件夹本身的inode ……
- 内存容量越来越大,文件系统中的很多内容都能够缓存在内存中,因此很多情况下几乎不用担心磁盘的随机读问题。
上述三点,说明了当时的FS设计难以充分利用机械硬盘的顺序写入性能,另外,随机读问题可以通过内存中的缓存来得到缓解,因此剩下的最需要解决的问题是:随机小量写入怎么办?。
LFS对该问题提出的方案是:将所有随机小量写入都变成顺序大块写入。
如何将随机小量写入变成顺序大块写入?
这里将其分解为两个问题:
- 将随机写入变成顺序写入
- 将小量写入变成大块写入
随机写入变成顺序写入
先想想,之前文件系统导致随机写入的原因是:inode区域固定,另外还需要对inode是否空闲进行管理。我们可以将“inode放在固定位置”的这个想法去掉,在做修改的时候,我只需要往磁盘里写入足够我读取的信息就够了。
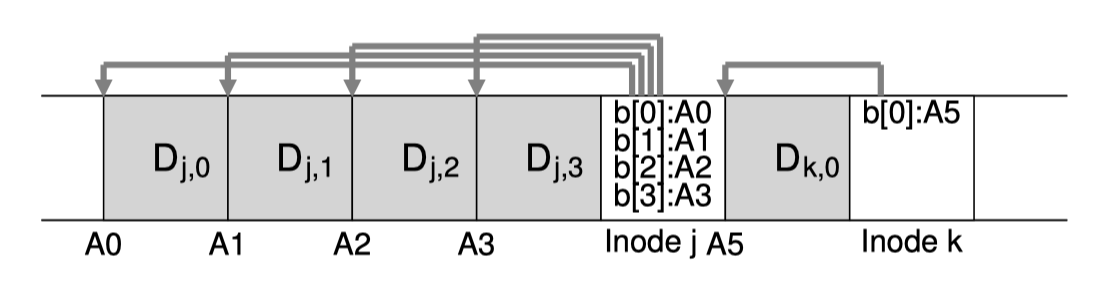 (图源《OSTEP》chapter43 P4)
(图源《OSTEP》chapter43 P4)
以上面的图作为例子,我创建一个文件j,那么我就把文件j的数据划分成多个数据块直接按顺序写下来。为了保证这些数据块可被索引,我们还需要将包含索引指针的Inode写下来,如上图所示,我们就直接写到文件数据块后面。对于另一个文件k也是如此。
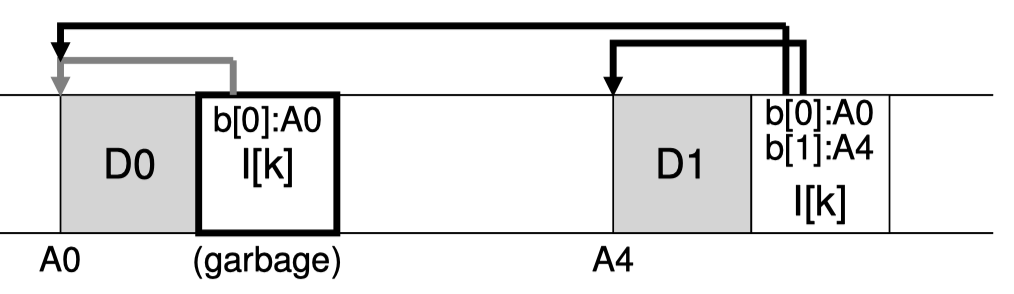 (图源《OSTEP》chapter43 P9)
(图源《OSTEP》chapter43 P9)
而对于修改文件数据操作,我们也可以使用类似的方法,如上图所示,创建文件k之后,我们增加了一些数据,因此在后面我们将新加的数据块直接写下来,然后我们在原先的Inode上新增加了一个索引指针,再紧接着数据写下来。(可以发现旧的inode成为了垃圾,因此后面需要做垃圾回收)
通过这样的策略,我们就可以将任意的创建和修改操作都变成顺序写操作,只要我们能够找到Inode,就能找到整个文件。
小量写入变成大块写入
顺序小量写入依然存在问题。考虑这样一个场景:有大量连续的小量操作需要写,但是在写了一点数据后,可能会:1)别的程序也需要写数据,这会可能会导致磁头移动到别的区域。(尽管OS中的I/O调度器可以合并顺序小I/O) 2)在小I/O之间隔了一点时间,在这段时间里,磁盘刚好转过了下一个扇区,这导致我想要顺序写入,要等磁盘再转一圈。
上述两个问题,说明了机械硬盘中小I/O的低效性。因此LFS一方面将随机写入都变成了顺序写入,另一方面,其会将写入操作都暂时写在内存中,将其称之为一个Segment(或者说是memory buffer),等攒够了足够的数据再一次往磁盘写入。
总而言之,解决了这两个问题,LFS最终实现将所有随机小写变成了顺序大写操作。当然,这是有代价的,其代价是,暂存在内存中的数据将会面临丢失的风险,一旦意外掉电,内存中暂存的数据将会不可恢复。
问题:内存暂存的块应该选多大?这是一个数学题。考虑到每次写入一个块需要一次寻道。越大的块,意味着分摊到单位大小的寻道时间越小,换一种理解,就是寻道时间在I/O时间的占比就越小。我们可以预先设定一个占比,然后返回来计算此时内存中暂存的块大小即可。
如何读取/寻找到指定文件?
前面对写入已经写得很清楚了,LFS并不改变Inode内部的形式,仅仅是将Inode从存放在固定区域变成随数据散布在磁盘中(有一种说法是Floating Inode)。这带来的问题是,以前可以简单的用Inode号计算Inode在磁盘中的偏移量进而找到Inode在磁盘中的存储位置,现在不好找了。
这一部分,我们解决两个问题:
- 如何通过Inode号,找到Inode本身?
- 如何处理文件夹的目录表?
如何通过Inode号,找到Inode本身?
这里需要额外增加一个叫Inode Map的数据结构,该数据结构的作用就是通过Inode号得到Inode磁盘地址,其形式和“索引指针”类似。如下图所示,该结构简单的将Inode号分成多个范围,每个范围使用一块Inode Map,然后再使用一个Inode Map的Map(相当于间接索引指针)将这些数据块组织到一起。
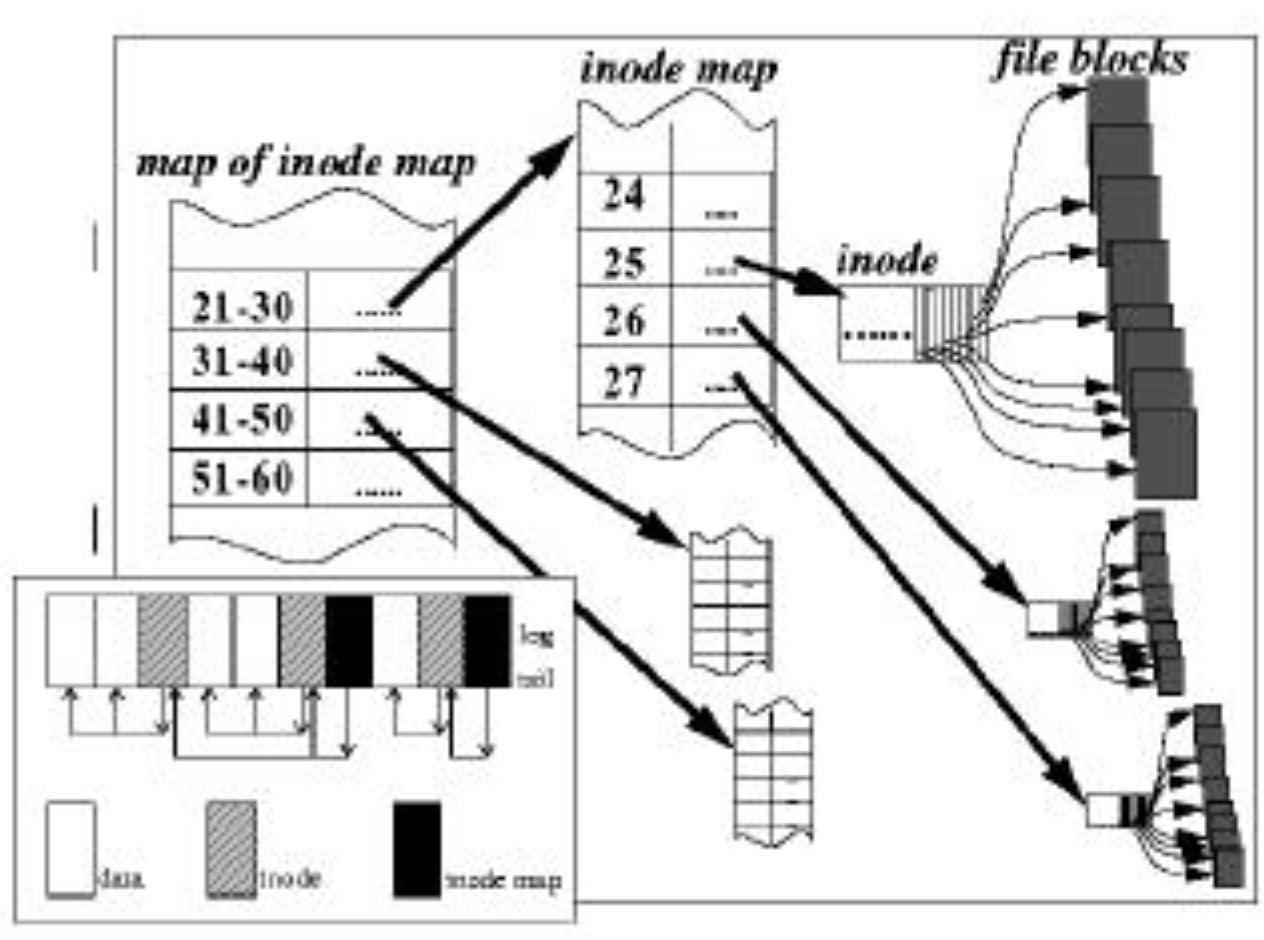
(图源:Log Structured FS-Arvind Krishnamurthy)
现在的问题是:这个Inode Map如何存放在磁盘中的?如果存放在固定的位置,那么依然会带来大量随机写入。LFS的做法是:依然将其以Log的形式,和数据写在一起。
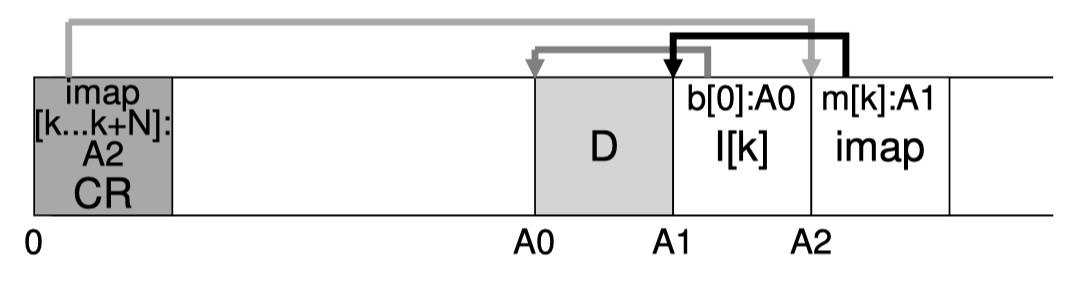 (图源《OSTEP》chapter43 P7)
(图源《OSTEP》chapter43 P7)
如上图所示,当我们创建了文件k,因此写入了数据块和Inode后,我们还会在数据后面紧跟着将增加该新Inode后的对应的Inode Map写下来,其存放了一部分Inode到磁盘地址的映射关系。因此Inode Map本身适合数据一起顺序写下来的。
而Inode Map的Map,会存放在磁盘上的一块固定的地方,叫做Checkpoint Region(图中的CR),实际上LFS并不会频繁修改磁盘上的CR,因为Inode Map的Map足够小,一般情况下可以只在内存中做修改,定期(如30s)写回磁盘就好。这样能够最大限度的避免对CR修改造成的随机写入,同时也尽量让数据保证持久,避免丢失。(如果真丢了一些Inode Map的Map,怎么办?后面会写)
如何处理文件夹的目录表?
一般而言,文件夹目录表会以(文件名、Inode号)的形式存放在文件夹对应的数据块中。我们考虑这样的一个问题:文件夹目录表如果存放的是(文件名,Inode号,Inode磁盘地址),这样子,是不是就不需要额外的Inode Map做转换了呢?
听起来是挺美好的,可以直接读到Inode的地址,然后就能读到每个文件了。但,问题在于:如果修改了一个文件,如增加了一个数据块,我就需要给该文件创建一个新的Inode,这会导致其父目录中的目录表的某一项无效(因为其存了Inode磁盘地址,但现在创建了新的Inode),我们就需要再写入新的数据块修改父目录的目录表,因为增加了数据块,父目录的Inode也要修改,因此又需要创建新的Inode,这又会导致其父目录的父目录中的目录表的对应项无效……
通过这个例子,我们说明使用Inode Map来处理Inode号到具体Inode磁盘地址的映射关系,这一层额外的间接寻址,是有必要的。
如何进行垃圾回收?
我们对LFS的读写都算是弄清楚了,但是我们也能发现,Log-structured式的写入,会带来一个问题:修改数据时会产生大量的无用历史数据。
(图源《OSTEP》chapter43 P9)
如上图所示,往文件k新加的一个数据块,导致了旧Inode的无效。我们此时可以有两种做法:
- 化bug为feature:历史数据都还在,我们可以基于这个旧的Inode,作为一个文件的旧版留着,那么这个文件系统就能够保证用户的修改不会丢掉任何数据,只要我想,我就能把文件的版本回退到指定的旧版。
- 将无效的数据作为垃圾清除掉,腾出额外的空间出来给未来的写入。这就是垃圾回收。
LFS采用的当然是垃圾回收策略,常称为Segment Compaction,顾名思义就是让有用数据存放的更加紧实。为此,我们需要探讨四个问题:
- 判断什么块是垃圾?
- 如何进行垃圾回收?
- 何时进行垃圾回收?
- 该回收什么垃圾?
什么块是垃圾?
在修改数据中,我们并没有办法对无效的数据块进行标记(否则就需要带来随机写入),这意味着我们需要读取这些log,通过log中含有的信息来判断其是否是垃圾。
判断Inode是否是垃圾很简单:读到Inode后,再从Inode Map中找一下,看看里面存的Inode地址和我现在读到的Inode地址是否一样,不一样就是垃圾。
判断Inode Map块是否是垃圾也很简单:读到Inode Map,一样从CR找一下,这个范围内的Inode Map是不是我这一块,如果不是,也是垃圾。
判断数据块是否是垃圾则要复杂一些。我们需要Inode号,以及数据块的偏移量Offset来确定一个数据块的身份,然后再去文件系统中读取该Inode号中对应偏移量的数据块,看其磁盘地址是否和我目前读到的这一块相同,如果不同,就是垃圾。为了更方便的进行垃圾回收,LFS将一个Segment中的所有数据块,其磁盘地址、Inode、偏移量,都存在了Segment Summary Block中。
如何进行垃圾回收?
知道了什么是垃圾,我们也不好做回收。想象一下,一个Segment里面有些块是垃圾,另一些块不是垃圾,如果我真的要回收掉这些零零碎碎的空间,我们会造成磁盘内大量的零碎的空洞,这些空洞并不能帮助我腾出空间,存下一整个Segment。
LFS的做法是:以Segment为单位拿出来做垃圾回收,当遇到其垃圾块,不管,如果是有用的数据块,则将其当做是“新写入的数据块”直接往现有的LFS中写入。这样做是不会改变LFS内容的。另外,将其有用的数据直接以类似“重做”的方式写入LFS后,我们就可以回收原来的一整个Segment,这样腾出来的空间就可以为未来的写入服务,原先不连续的有用数据也得以紧密的排列在一起。
何时回收哪个垃圾?
这些属于在LFS的实现中需要考虑的一些具体策略。
关于何时回收垃圾,一般的考虑是优先保证用户体验,尽量无感回收。因此我们可以选择在磁盘空闲的时候进行回收,也可以阶段性的进行回收,以及在可用空间不足(但实际空闲空间足够)时强制进行垃圾回收。
而关于回收哪些垃圾,这是我们需要考虑的另一个策略。考虑一个策略的好坏,我们可以从以下几个角度来考虑:
- 需要做的额外I/O的量有多大?
- 选择的Segment垃圾数据是否足够多?
- ….
LFS提出的策略是:先回收“冷”的数据块,再回收“热”的数据块。这种策略的考虑是:
- 冷的数据块,其中的数据要么是垃圾,要么是稳定几乎不变的有用数据。将其回收后得到的数据块应该可以得到全是有用的几乎不动的Segment,垃圾比例更小,这一个Segment以后也许再也不用被回收了,不用做更多的额外I/O。
- 热的数据块,其经常会有数据被修改和覆写(如某个文件被重复读写),这说明该Segment在未来很可能会有大量数据变成垃圾,所以我不着急对它进行回收,等一等,等到未来不怎么操作了,这个数据冷了,再回收。(如果热的时候进行回收,那么可能会有回收重做完,这个数据就变垃圾了,这次的垃圾回收就做了额外且无用的I/O)
实际上还有很多很多种不同的策略,就不详细描述了。
崩溃后如何恢复?
作为一个文件系统,崩溃恢复是一个必须考虑的问题。我们可以想想,在不同的情况下,LFS突然崩溃了,需要如何处理?如何保证LFS的一致性不被损坏?
- 内存中的Segment还没存下来,突然崩溃了。
- 这种情况没法救,这是LFS的最大的弊病。
- 内存中的Inode Map的Map存了一个旧的到CR中,最新的没存下来。
- 这个其实可以恢复。考虑到每次对Inode Map的修改都会写在log中,我们可以遍历log,找到最新的Inode Map(Inode Map中会存时间戳),然后更新之前恢复的旧的Inode Map的Map即可。
- 内存中的Inode Map的Map写到一半崩溃了。
- LFS的做法是,Inode Map的Map会存在两个CR中,一个坏了读另一个就好。
- 实际的做法是:根据CR的写入时间戳来判断,找时间戳旧的那个,肯定没坏。
- 在做写Log操作是崩溃了
- 考虑到写Log时的数据都是先写数据,再写Inode,如果读到了Inode意味着数据是完整的。如果读不到Inode则意味着数据可能损坏,那就丢弃掉。
相关改进
- 优化Segment Compaction。
- 在超过90%的数据都是有用数据时,LFS中可能存在相当多的空洞,而几乎没有空闲的Segment,这个时候写入数据就需要和Segment Compaction同步进行,大大降低性能。该文章[2]提出了Thread Logging方法,在快满的时候,不进行Segment Compaction,转而直接填Segment中的空洞,同时还提出了一个策略,在空Segment较多时使用Segment Compaction,空Segment较少时使用Thread Logging。
参考资料
- 《Operating System: Three Easy Pieces》:Chapter 43 Log-structured File System
- CS 161: Lecture 15
- Log Structured FS-Arvind Krishnamurthy