Log-Structured Merge-Trees
Updated: Aug 4th, 2021
摘要
背景: 磁盘(无论是HDD还是SSD)随机操作慢,顺序读写快。
问题: 现有的读日志方法,虽然提高了日志的读取性能,但却因为增加了一些随机读写操作,牺牲了较大的写性能。另外,一些现有的需要持久化的索引结构,也增加了一部分随机读写。
原理:尽可能使用顺序读写。
实现方法
以使LSM Tree实现一个KV存储为例
整体架构
整体由内存中的一个SSTable和disk中的SSTable组成。
图源:1
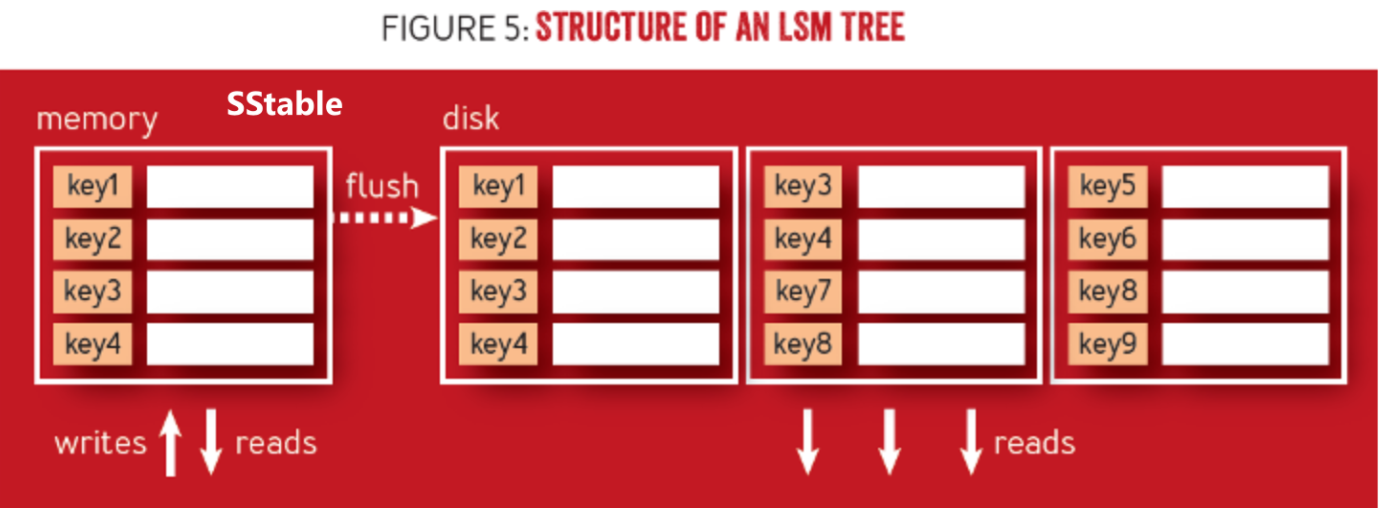
其中,内存中的SSTable含有一下几个特点:
- SSTable中按key排序
- 通常会有一个内存中的数据结构(如b树等)作为索引。
- SSTable中的每一行除了有key、value,还会有timestamp记录该操作的时间戳。
图源:2
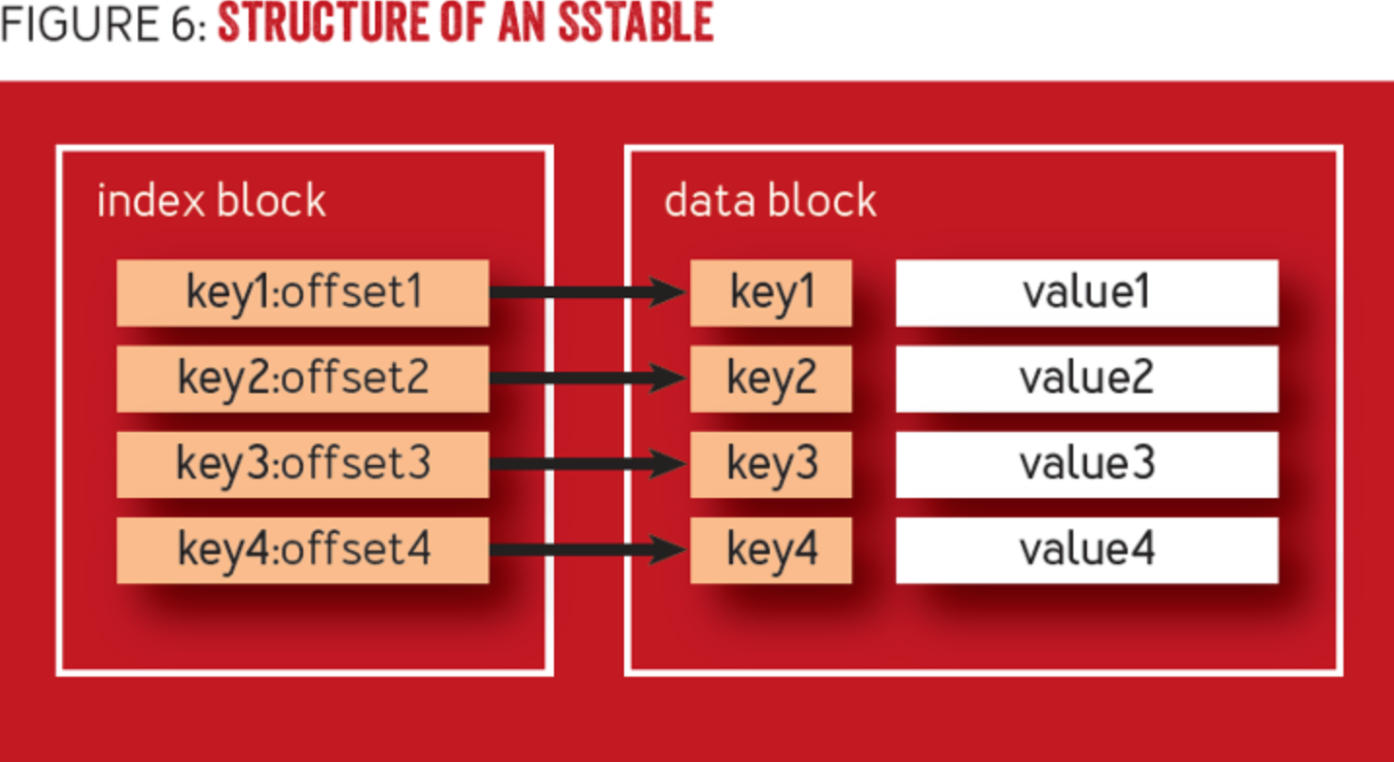
如何写
向该KV存储写入新的k-v对的方法为: 1. 直接向SSTable的datablock末尾增加一行新的kv 2. 更新索引结果 3. 如果SSTable的大小达到了设定的阈值 1. 将SSTable flush到硬盘上
可以看出,关于写,在LSM Tree的方法下 1. 内存写,速度快 2. 在写盘的时候将随机写变成了批量顺序写。
当然,为了保证持久性,在写的时候一般会有Write Ahead Log技术的支持。
如何删除
在SSTable中增加一项 key->deleted的特殊项,和普通的写没有区别。
在后面读的时候,会根据时间戳来寻找最新的一项,如果最新是标记了deleted那就不会读取这个key了。
如何读
因为SSTable中是按照Key排序,而不是按照时间戳排序,因此不能够直接在SSTable中倒序搜索,而是真的要读取所有SSTable,寻找其中时间戳最新的那一个记录,才能够读取到。
因此需要定期的合并来整理SSTable。
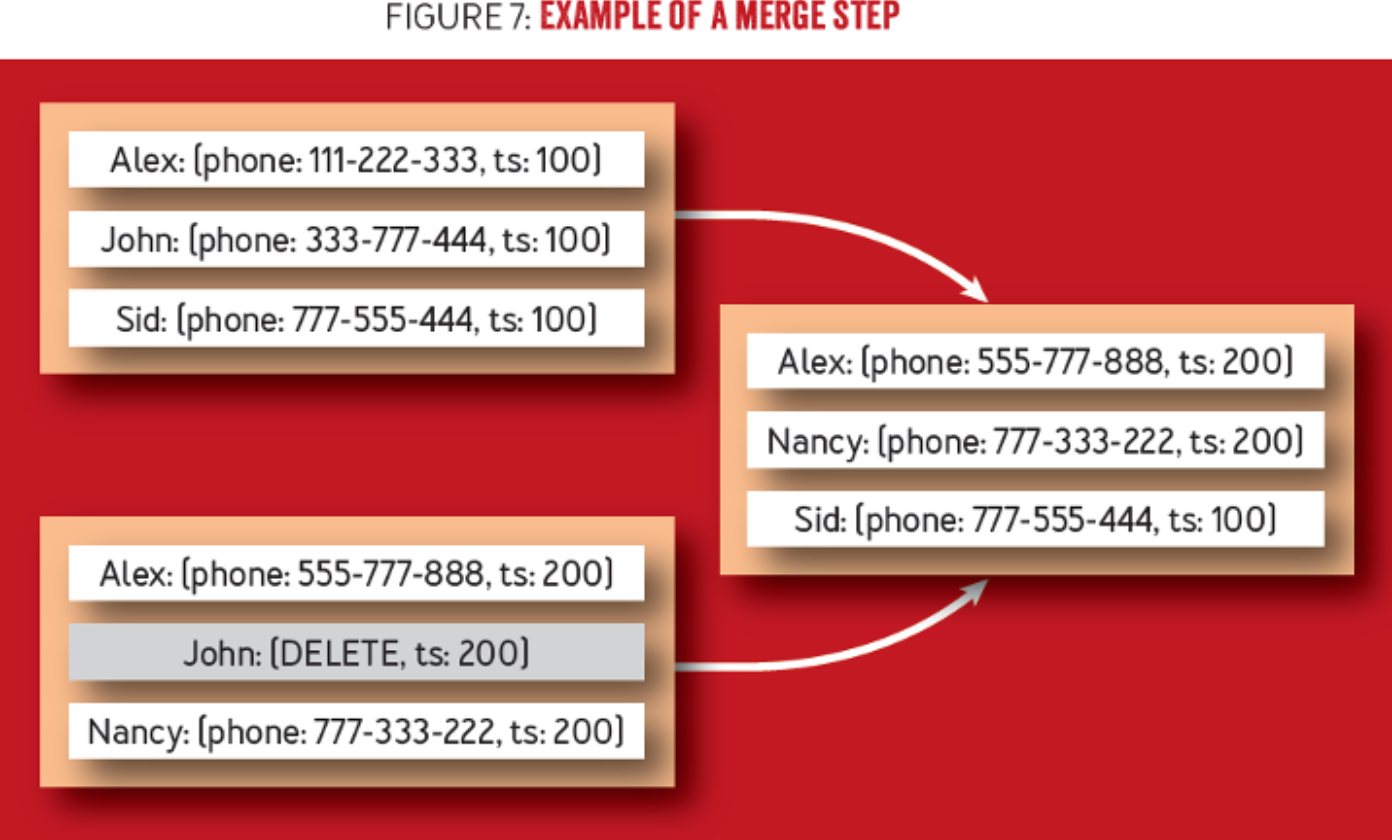
如何合并
合并的目录3: 1. 减少冗余,移除重复的更新和删除记录。 2. 保证读性能。
如何合并:因为SSTable都是按key排序的,所以合并的过程与归并排序类似。
图源4
比较
- LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能5。