OSDI'21 存储类文章
Updated: Aug 11th, 2021
在OSDI’21的Storage Track中,Session Chairs是:Dushyanth Narayanan和 Gala Yadgar。Dushyanth Narayanan是微软Holographic Storage Device for the Cloud项目和FaRM项目中的Senior Principal Researcher(高级首席研究员)。Holographic Storage(全息存储)看起来是下一代的归档型存储,FaRM项目则和RDMA、分布式一致性有关。Gala Yadgar是来自以色列理工大学的副教授,看个人介绍也是一个纯粹做存储系统的学者。
然后来点评分析一下OSDI’21中位于Storage Track的五篇文章:[1],[2],[3],[4],[5]
Modernizing File System through In-Storage Indexing
主要贡献者来自韩国的DGIST。
这篇文章主要想解决的问题是:文件系统的扩展性问题。众所周知,随着存储设备的发展,现代存储设备的延时越来越低,带宽越来越高,然而现在的内核文件系统在一些操作上并不能够充分利用如今存储设备的性能。如下图所示,用着最快的SSD,但是create/rmdir操作的吞吐量依然上不去,跟不上如今SSD性能的提升,显然该操作的瓶颈已经从硬件端上移到系统软件层了。
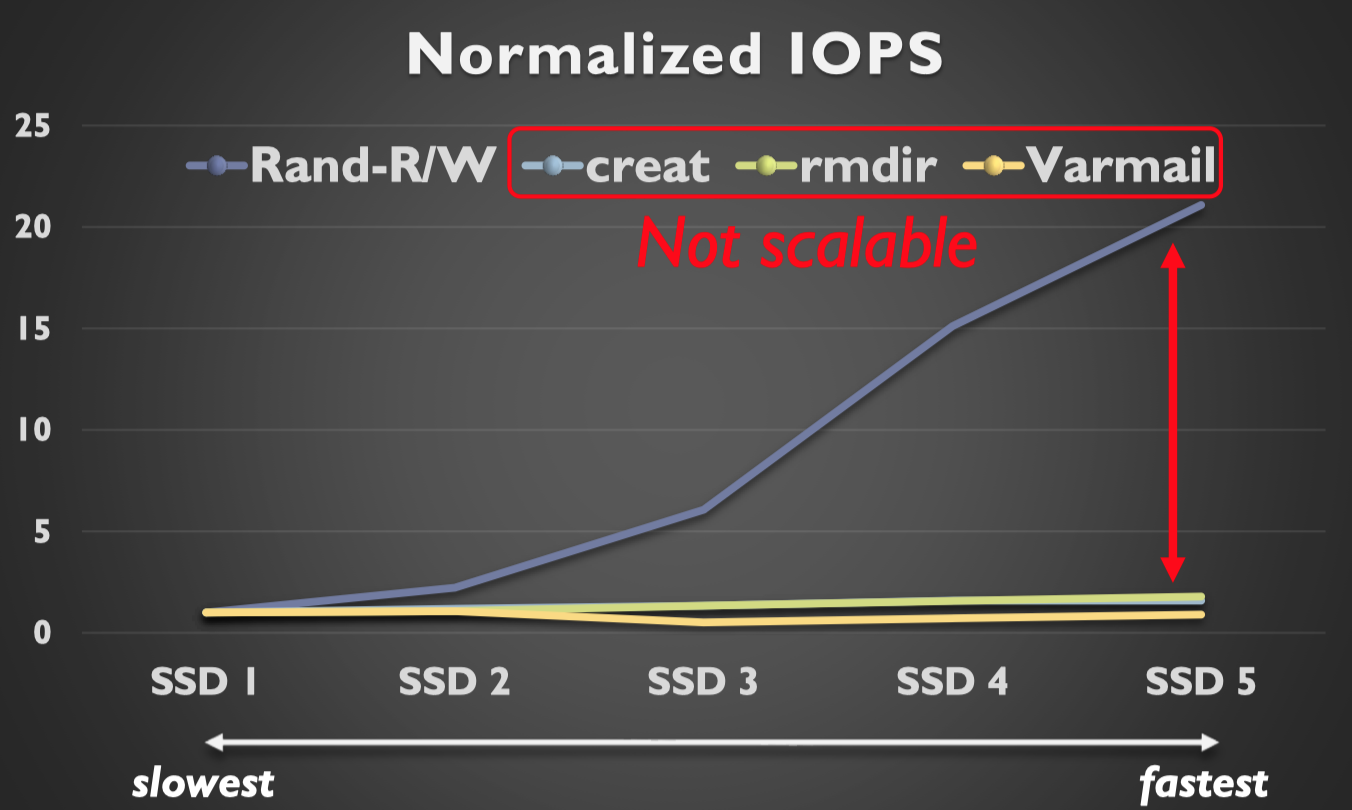
怎么解决这个问题呢?这里的一个关键观点是SSD抽象出来的块设备接口比较简单,为了在这个块设备接口上完成对文件的抽象需要操作很多额外的数据结构,要维护一些元数据,还要增加日志处理从而保证崩溃可恢复性。这些都导致文件系统任务量比较大,而设备处却闲着。那不如把文件系统的一些工作下放到SSD中完成,本篇文章的思路就是这样:
- 将SSD对外暴露的接口从块设备接口改成KV接口,并在SSD的闪存芯片上基于FTL实现了一个类似LSM的KV存储。
- 实现了一个基于KVSSD接口的内核文件系统。
关于 [[ KV-SSD ]]这一个我确实还不太了解,以后考虑调研一下相关文章。
Nap: A Black-Box Approach to NUMA-Aware Persistent Memory Indexes
来自清华舒继武、陆游游团队。
这篇文章想要解决的问题是:目前在PM上做的并行索引数据结构都是在单个NUMA节点内的,而如果想要扩展存储空间的话,必须要跨NUMA使用PM。如何将已有的并行索引数据结构扩展到NUMA架构的机器里?
ASPLOS’17有篇文章[6]是在DRAM做NUMA-aware的数据结构,其提出了Node Replication(NR)方法在每个numa节点上复制一个数据结构副本,这样子无论在哪个副本上进行写操作,我都只需要写本地副本就好,读操作的话,每个numa节点都有一个副本,自然不需要读remote memory,然后这几个副本通过一个共享的log来进行同步,同步的开销也比较小,但这种方法在PM上行不通了,原因如下:
- 从容量来看,使用PM就是想用大容量优势存储更多东西,但开副本直接把能用的容量折半再折半了。
- 从写放大来说,一个写入在副本后变成了多个写入,写放大成倍增加,影响寿命。
- 从性能来说,PM跨NUMA性能下降比DRAM更严重,原本通过一个share log同步的方法也成了影响性能的重要因素。
综上所述,在DRAM上做NUMA-aware的数据结构的方法在PM上不适用,因此这篇文章提出了一个叫Nap的方法用来将PM上的并行索引数据结构转成NUMA-aware的,大概思路是:
- 只处理热数据。具体地说,就是冷数据原来怎样就怎样(有remote memory access也不管),只对小量的热数据进行处理,实现热数据的numa-aware。
- 读取:热数据cache在内存里。因为热数据量比较小,可以完全存在内存中,这样子对热数据的读取就有了优化,也不用担心pm的numa问题。(DRAM无论是否NUMA,性能都非常好,比PM好多了)
- 写入:写热数据时,哪个线程开写,就写在该线程对应的本地PM中,同时版本号+1,并更新到DRAM中的cache。版本号的功能是帮助判断最新的结果。
这样子无论如何读写热数据,都不会访问远端pm。
Rearchitecting Linux Storage Stack for µs Latency and High Throughput
来自Cornell的Rachit Agarwal,也是老朋友了。
要懂这篇需要一些blk-mq的背景知识。在blk-mq中,软件队列和硬件队列之间的关系往往是一对一的,一个软件队列一定对应一个硬件队列。这个会在这篇文章构造的这样的场景中造成问题:一个Latency-Sensitive应用和一个Throughput-Sensitive应用使用同一个核进行I/O。如果使用blq-mq进行I/O,那么吞吐量应用确实能吃满吞吐了,但是这个时候就会让使用同一个队列的延迟敏感性应用很慢,队列被吞吐量应用占满了,导致Head of Line阻塞。如果换成spdk呢?spdk的I/O是基于pulling的,两个应用都要分出一个线程进行pulling,这两个I/O线程在同一个核上基于CFS调度策略不断切换,同样会使长尾延迟较高(考虑调度粒度)。
本篇文章基于blk-mq来尝试解决这个问题。在blk-mq中,硬件队列和软件队列之间的映射关系并不灵活。一方面,多个应用同时用一条队列会导致
一个核上软件队列和硬件队列的映射关系虽然可以动态改变,但这个映射关系一定是一对一的,这一方面导致多个应用同时使用一个核时,公用队列导致的Head of Line阻塞影响延迟,另一方面是不能充分利用多个硬件队列尽可能提升吞吐量。本文对软件队列和硬件队列的映射关系进行了解耦,作者的说法是:像一个交换机一样,实现Ingress queue 和 Egress queue之间的数据传输。从而实现以下几个目的:
- 不同类别的应用,用不同的软件队列和硬件队列。
- 一个软件队列可以对应一个硬件队列,也可以对应多个硬件队列,来应对吞吐量应用。
- 不同队列之间有不同的优先级,Ingress queue和Egress queue之间的映射关系可以在运行时根据负载动态调整。
这里需要注意一个,关于应用类别,blk-switch的做法是,需要用户在系统调用中提供一个额外的flag告知OS。如果不告知,blk-switch也可以猜。
Optimizing Storage Performance with Calibrated Interrupts
这篇文章是一个典型的trade-off型文章。
极端1:对于每个I/O请求的完成,都使用一个中断来收割。 好:tail latency好 坏:IOPS上来了,中断开销会非常非常大 极端2:对于每个I/O请求的完成,都等一等,等一段时候后再一次收割。 好:吞吐量好了,可以分摊中断开销 坏:tail latency差
这里就实现了一个 1. 应用感知:不同类型应用用不同的策略,有的用中断有的用攒。 2. 自适应:自适应调整攒的超时时长。
具体的实现,是需要用户提供应用类型,对于延迟敏感性的就尽快中断,对于吞吐量型的用攒的方法。
ZNS+: Advanced Zoned Namespace Interface for Supporting In-Storage Zone Compaction
三星和韩国成均馆大学合作的成果。
LFS和ZNS SSD这两者其实是绝配,只要把Segment和Zone搭配上就能够充分利用好ZNS SSD了。但是这里的问题是:LFS需要进行Segment Compaction(就是LFS中的垃圾回收),这需要LFS将需要回收整理的Segment从ZNS SSD读上来,然后进行整理,再紧实的写到SSD中,腾出一些空Segment来。这个过程需要Host相当多的计算资源,并且还会占用主机-SSD之间的带宽。
这篇文章主要针对Segment Compaction的开销进行优化,优化的方向是:
- 通过将Segment Compaction卸载到SSD本身,降低开销。他们在ZNS基础上增加了接口zone_compaction,当FS确定好了需要被回收的zone后,将其相关地址和长度通过该接口发送到SSD中,由SSD自身完成数据的拷贝工作。
- 在需要的时候切换到Threaded logging,而不使用Segment Compaction回收空间。Threaded logging是一种LFS中的技巧,其不进行segment compaction,而是直接在现有segment的空洞中写数据。ZNS本身并不支持在空洞中写数据(带来随机写),这篇文章在ZNS基础上,增加了接口TL_open来支持thread logging。
除了上述两个优化方向,本文章还提出了两个优化细节:
- copyback-aware block allocation: 复制的源和目的如果处于同一个chip中,可以在chip内部复制,进一步加快,因此可以在分配的时候,就尝试让目的和源尽可能靠近在同一个chip中。
- hybrid segment recycling:就是自适应的在segment compaction和thread logging之间切换。
Notes mentioning this note
There are no notes linking to this note.