Zone Namespace SSD
Updated: Apr 19th, 2024
Zoned Namespaces是NVMe规范中的一套新命令集(Zoned Namespace Command Set),该命令集暴露了一套接口(zoned block storage interface)给主机,该接口将其容量划分为多个Zone,在每个Zone内允许随机读,但只允许顺序写。这样的设计简化了SSD内部的数据放置策略,能够让写入的数据与物理介质对齐,并能够优化吞吐量、QoS、容量、寿命等。但用好这种读写接口需要用户软件层的额外适配。支持 Zoned Namespaces 命令集的SSD便成为Zone Namespaces SSD(ZNS SSD)。
1. 为什么需要ZNS接口
在这一部分中,首先先写目前普通的SSD存在的一些问题,再来说说为什么ZNS SSD具备解决这些问题的潜力。
1.1 传统SSD存在的问题
首先是传统SSD需要进行垃圾回收操作。传统SSD将逻辑地址和实际物理地址之间的关联完全隐藏起来交由SSD中的FTL来管理,上层应用仅能写到LBA中,FTL则将任何应用的写入操作一起处理,混合的写入到SSD中。如下图所示,这导致不同的文件将会散乱在SSD中,删除一个文件会造成大量的空洞无法得到有效利用,进而需要将有效的数据读出来以更紧密的方式写到新的块中才能将零散的空洞集合成可用的空闲块。这样的垃圾回收会带来问题:1)写放大问题:同一块数据可能会被重复读写好几次。2)长尾延时问题:垃圾回收时会占用额外的SSD读写带宽与控制器处理资源。3)闲置空间浪费:为了进行垃圾回收,需要留一些额外的空间用于写入紧密的数据,这部分空间不能被用户所使用(留出额外空间的特性称为Over Provisioning,简称OP)。
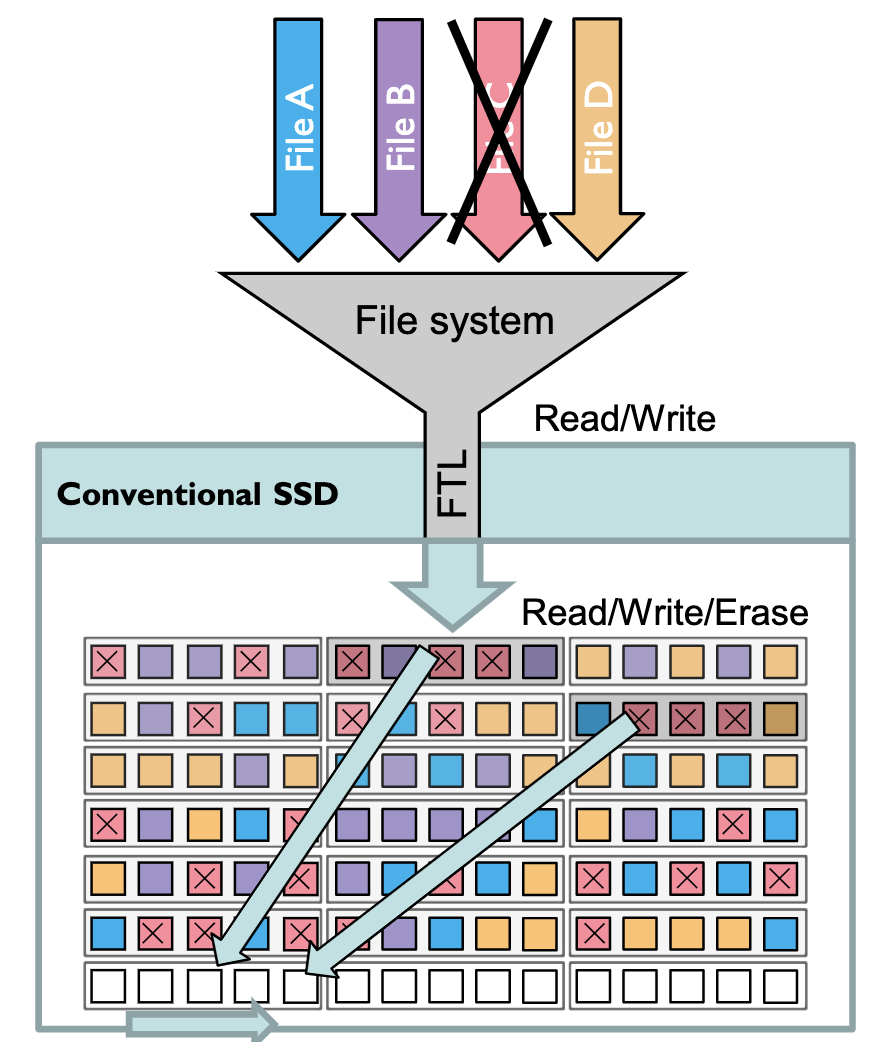
(图源:Zoned Namespaces (ZNS) SSDs: Disrupting the Storage Industry)
传统SSD的另外一个大问题是log-on-log问题。如下图,RocksDB为了保证数据的持久性,需要在写入数据之余写入write ahead log,带来额外写放大。在上面做了log之余,文件系统这一层又做了一次log,这次的log是做在LBA地址空间中。最后在SSD内部还会以log-structured的方式组织数据。这样在log上做log,带来了大量冗余,无谓的写入,同时也并不利于充分利用SSD的性能(毕竟SSD本来就会将各种写入以log-structure的方式写,上层也log-structured的话,并不一定比不log-structured好,反而会因为维护log-structured带来额外的开销)。
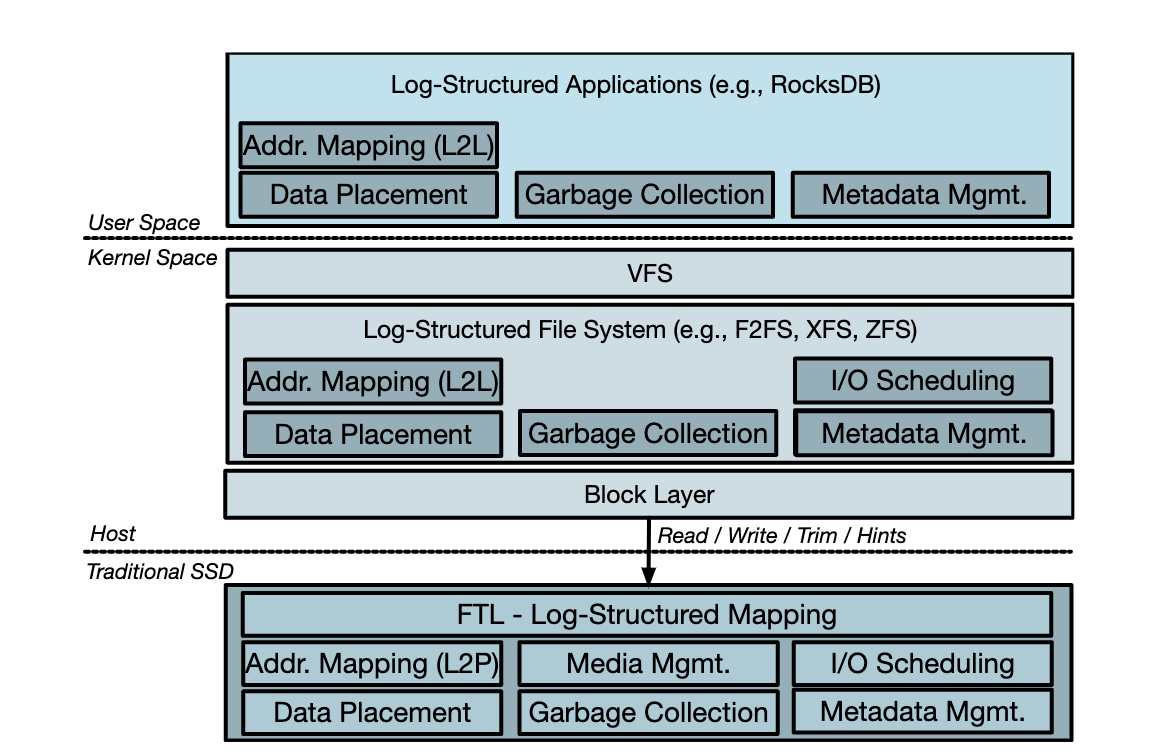
(图源:Zoned Namespaces : Use Cases, Standard and Linux Ecosystem)
最后还有一个问题是隔离性的问题。现在的场景更多的是在云中跑多个租户,这多个租户可能会使用着同一块盘,并且都有QoS的要求。而SSD原有的垃圾回收特性导致其难以保证QoS。另外其他租户的读写操作可能就意外引起一次垃圾回收,从而影响这个租户的性能。这导致不同租户之间的读写会互相干扰,性能隔离性很差。
1.2 ZNS的潜在优势
ZNS为什么可能可以解决上面的这些问题呢?先来简单说一下ZNS的一些特性:
- 将LBA分成了很多个独立的zone。
- 在每个zone内部只能够顺序写入,可以随机读取,擦除操作只能够以一整个zone为单位reset。
- 主机和SSD之间协同进行空间管理,可以保证zone和物理介质的对齐。(这里可能不能说完全没有垃圾回收)
- 需要主机来主动管理SSD上数据的垃圾回收。
关于垃圾回收,由于每个Zone内部只能够顺序写入,且擦除单位为一整个Zone,SSD已经不管用户的操作是否会导致垃圾数据的产生,因此垃圾回收的职责,从SSD自身上放到了上层的系统软件(如文件系统)。系统软件在操作ZNS SSD时,需要自己对垃圾数据做合适的标记,并且在合适的时间点主动触发(而不是被动地由SSD自身完成)。
因此,ZNS SSD中的垃圾回收是主机控制下的主动垃圾回收,这样避免了传统SSD难以控制的内部垃圾回收导致的长尾延时问题,保证了QoS。同时也让原有的Log-structured数据结构能够发挥更大的优势。另外,Zone之间的强隔离性,让多租户环境下的性能表现更为稳定。此处可参考下图。
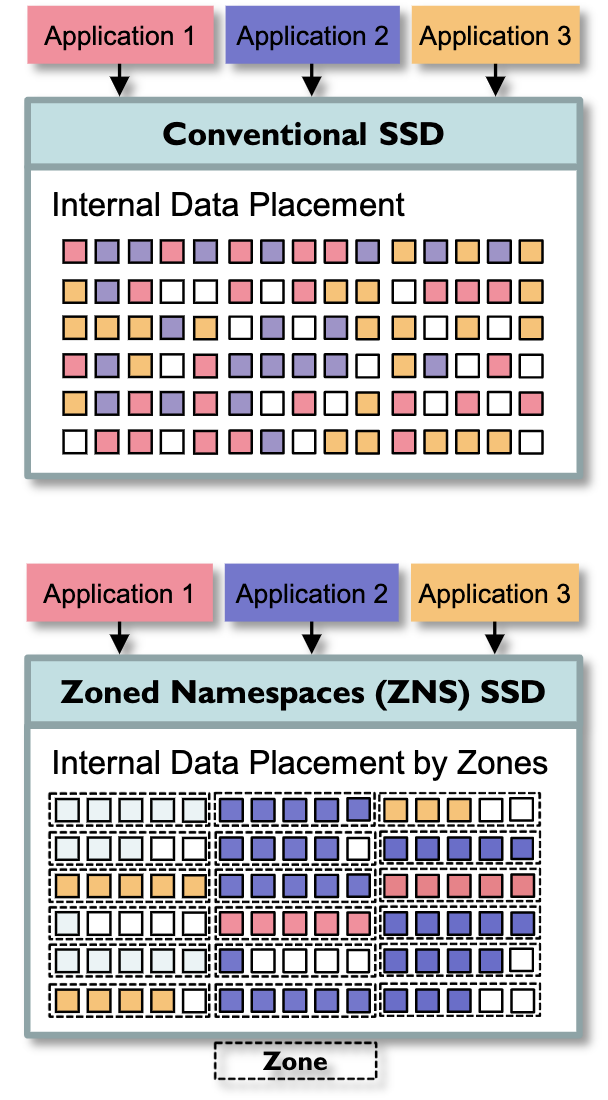
(图源:Zoned Namespaces (ZNS) SSDs: Disrupting the Storage Industry)
2. Zoned Namespace Interface
ZNS SSD需要支持Zoned Namespace才可以有上面提到的一些优势。Zoned Namespace是SSD中的一种特殊Namespace,在该Namespace中的SSD空间存储模型为Zoned Storage Model,支持Zoned Namespace Command Set。这一部分对这个规范的核心内容做一些讲解。
2.1 Zoned Storage Model
首先来说Zoned Namespace中的存储模型(Zoned Storage Model)。
对于物理Die到LBA的映射关系,不像是传统SSD需要存储很大的映射表,如下图,ZNS中LBA和实际的物理Die之间维护着一个固定的映射关系,这样LBA连续的地址,在物理块上也是连续的,另外还会横跨不同的Die以保证SSD原有的良好并行I/O性能。
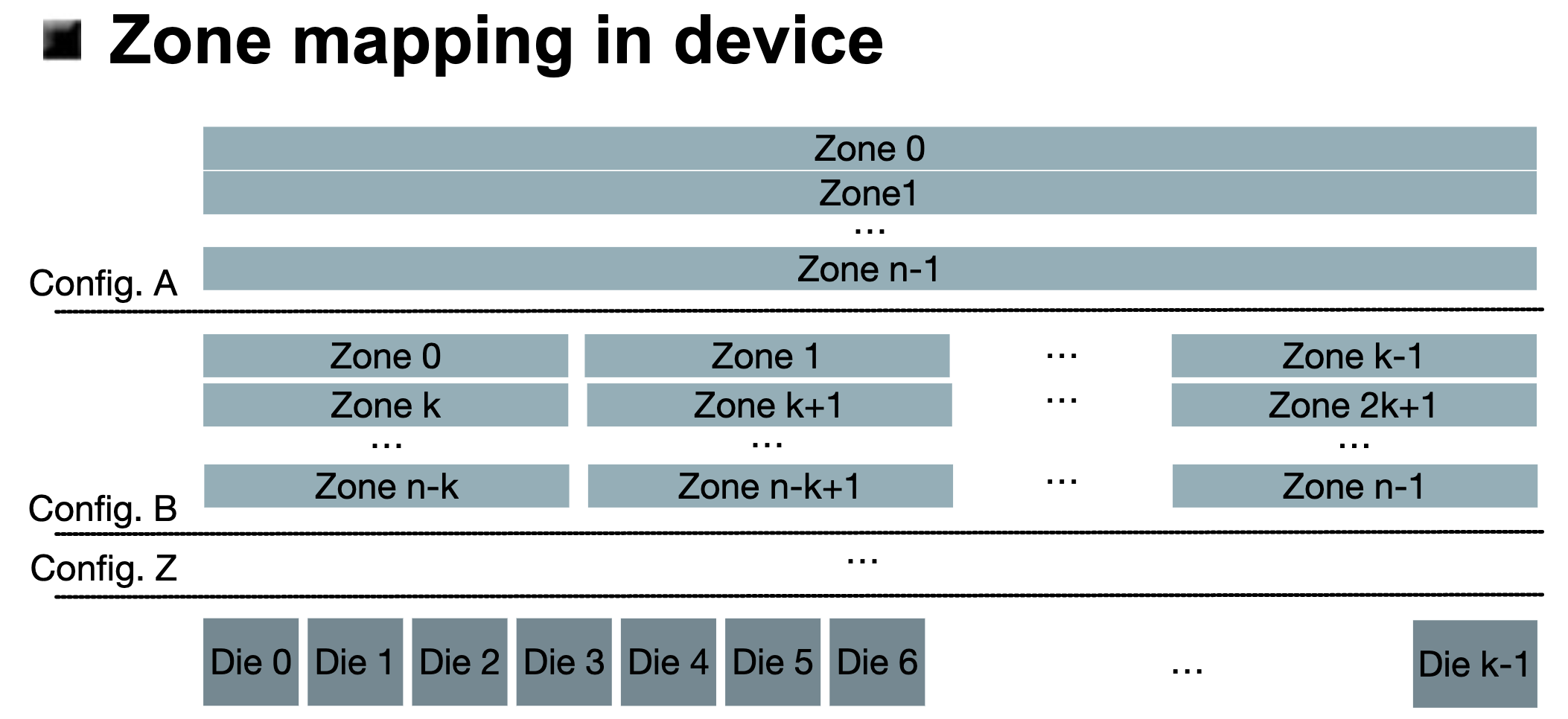
(图源:Zoned Namespaces : Use Cases, Standard and Linux Ecosystem)
而在LBA到Zone的映射关系中,ZNS中将LBA顺序分成了一个个Zone,每个Zone会使用一部分连续的LBA。这样看来,ZNS几乎直接将物理介质完全暴露到了上层软件中,由软件来对ZNS SSD的物理介质直接进行I/O操作,但同时软件也需要承担额外的负担,如磨损均衡,垃圾回收等。
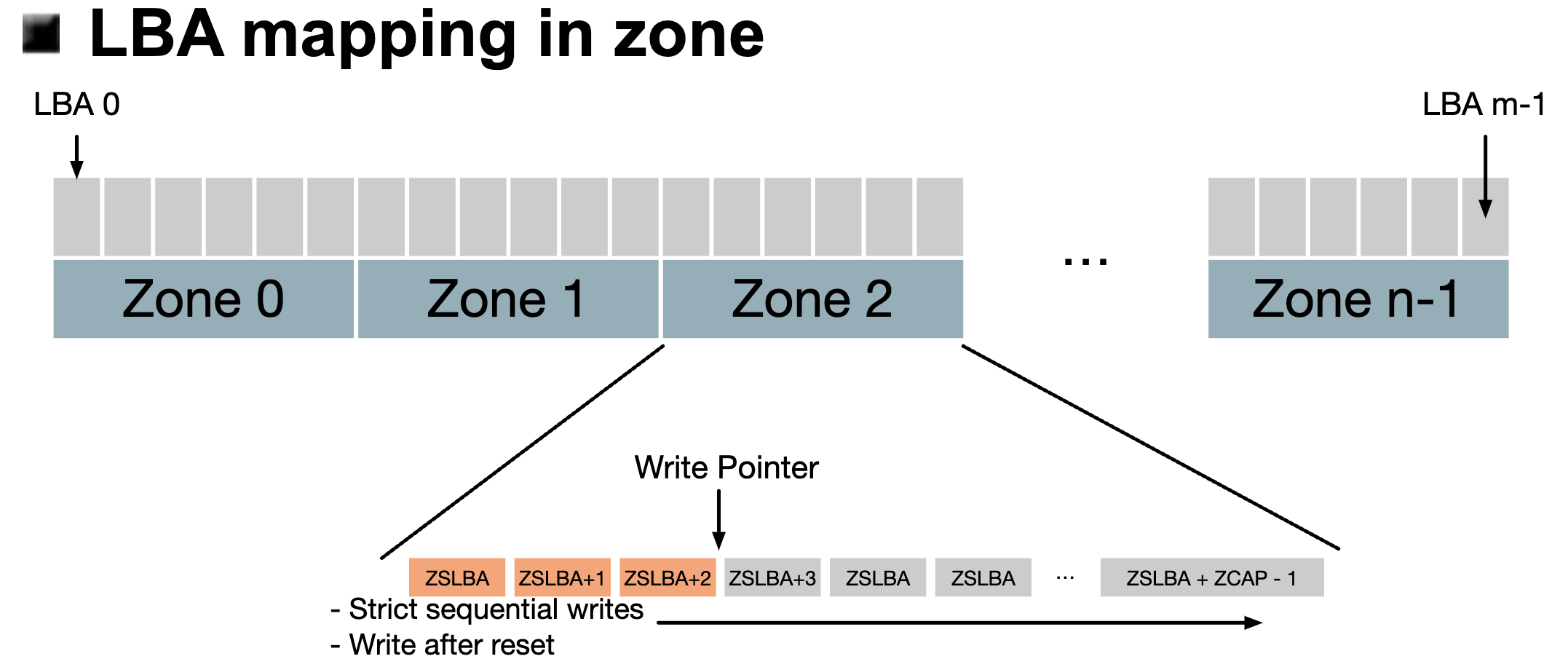
(图源:Zoned Namespaces : Use Cases, Standard and Linux Ecosystem)
Zone内部需要维护Write Pointer来保证顺序写入。在Zone内部的写入操作中,ZNS要求软件必须顺序写入,为了记住这个“顺序写入”当前写到了哪里,每个Zone都会有一个ZSLBA表示这个Zone开始地址(Zone Start LBA),Write Pointer表示偏移量,这个顺序写最多能写ZCAP这么多数据,也就是写到ZSLBA + ZCAP - 1。如果我不要这个Zone的数据了,我需要一整个Zone直接Reset,而不能够只擦除其中一部分。这里概括一下,就是:1)顺序写入,2)随机读取,3)整个Zone一起擦除。
每个Zone都可能很容易写满,这个时候SSD就要提醒用户新开一个Zone,这就需要每个Zone内部还需要维护一个“状态”。用户可以主动开启一个新Zone,此时会将该Zone会从是ZSE:Empty状态变成ZSIO:Implicitly Opened,再往里面写呀写呀,写满了,就会到ZSF:FULL状态,就会不让写,报错了。这个状态转移图可以参考下图,更细节的内容就要看文档了。
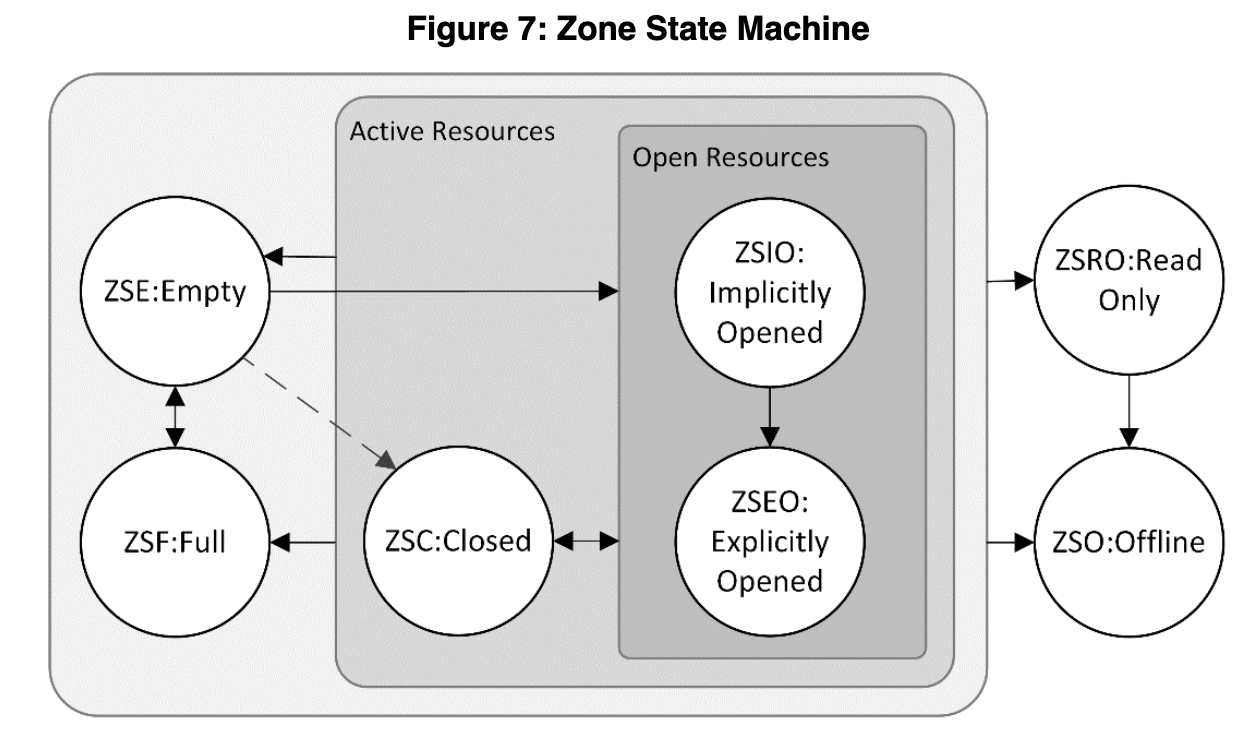 (图源:Figure
7: Zone State Machine)
(图源:Figure
7: Zone State Machine)
2.2 Zoned Namespace Command Set
弄清楚了里面的存储模型,我们知道了每个Zone需要维护这么一些信息:
- ZSLBA
- Write Pointer
- ZCAP
- Status(状态)
下面我们来看看在一般I/O的时候,ZNS SSD支持的命令集。
首先ZNS SSD能够支持从基本命令集的一些命令,如Flush,Read,Write,Verity等。
然后ZNS SSD能够支持一下ZNS特有的命令集,这些命令包括:
- Zone Management Send command
- Reset Zone, Open Zone, Close Zone, Finish Zone
- Zone Management Receive command
- 用于报告Zone描述符(Zone Descriptor)以及相关属性。
- Zone Append command
- 用于支持乱序写入,这是ZNS SSD的最大特点。
2.2.1 ZNS SSD中的Write指令
ZNS SSD中,我们可以使用一般的Write指令进行写入。在Write指令中,我们需要指定写入的块的地址LBA,然后调用Write指令。
我们需要注意到,NVMe中的SQ执行指令的顺序是不能得到保证的。为了最大化性能,NVMe默认会将SQ中的指令乱序执行,如果我在SQ中提交了多个连续写的Write命令,但是实际上乱序执行导致不能连续写入,这就违背了Zone内部写入的约束,会报错。因此ZNS中执行Write指令,每个Zone中的提交队列长度只能限制为1,这浪费了SSD良好的并行性,也降低了CPU的效率。
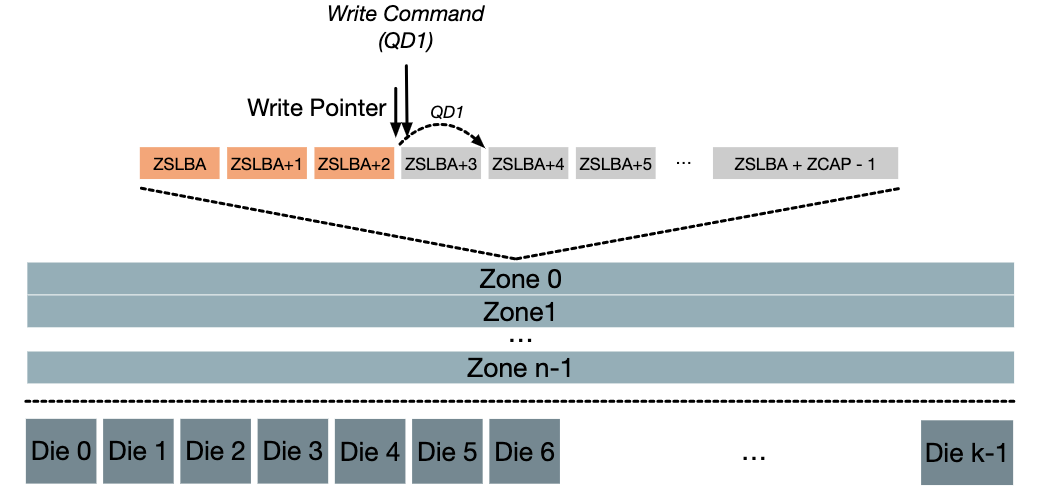 (图源:Zoned
Namespaces : Use Cases, Standard and Linux Ecosystem)
(图源:Zoned
Namespaces : Use Cases, Standard and Linux Ecosystem)
这里Write指令性能不好的原因是:必须在命令参数中指定写入的块的地址,如果不指定呢?这就是下面的Append指令。
2.2.2 ZNS SSD中的Append指令
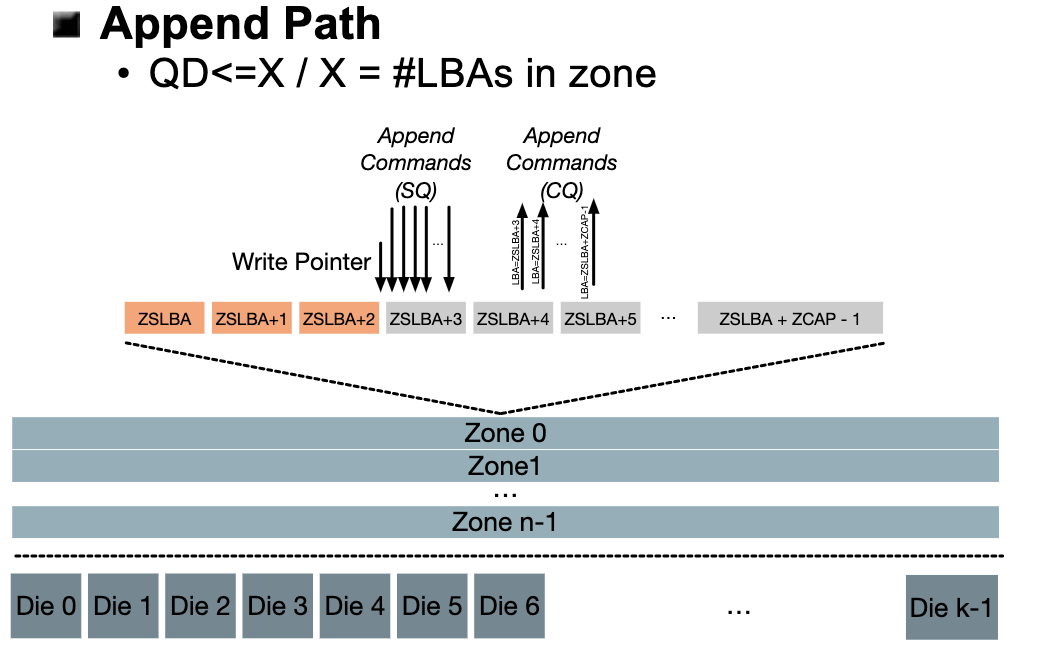
Append指令就是在已经有的数据中向后直接Append数据。如下图所示,一个Append指令需要一个输入LBA(实际上是Zone编号而不是具体地址),Len写入数据的长度,以及Data数据本身,返回的时候再返回实际写入的地址。
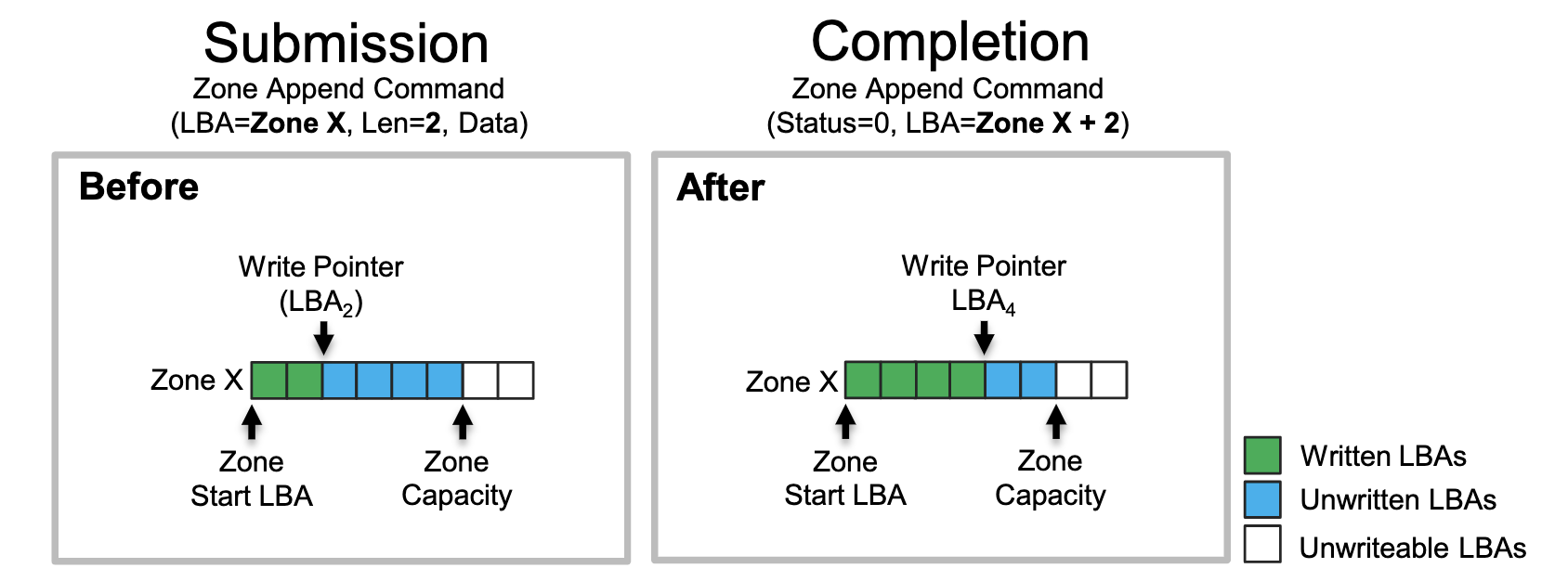
(图源:Zoned Namespaces (ZNS) SSDs: Disrupting the Storage Industry)
这样的做法大大提高了单个Zone中的并发写入操作数量。只要不限定每个数据写入的LBA的位置,只管Append,具体写入的位置让SSD来决定,然后返回实际的地址,这样的做法大大提高了SSD中乱序执行写入操作的能力,充分利用SSD中的并行性。
 (图源:Zoned
Namespaces : Use Cases, Standard and Linux Ecosystem)
(图源:Zoned
Namespaces : Use Cases, Standard and Linux Ecosystem)
但显而易见,这样的做法需要上层软件的支持。以往按照LBA分配并写入的逻辑不再奏效,在写入操作中涉及制定LBA的相关代码都需要重新实现以适配ZNS中的Append。
实际上,这种做法也在论文Nameless write[1]中提到过。
2.3 Extension
这里提两点ZNS SSD中的扩展,暂时还没列入到主线中,但也许是未来的主流。
- ZRWA(Zone Random Write Area)
- Copy
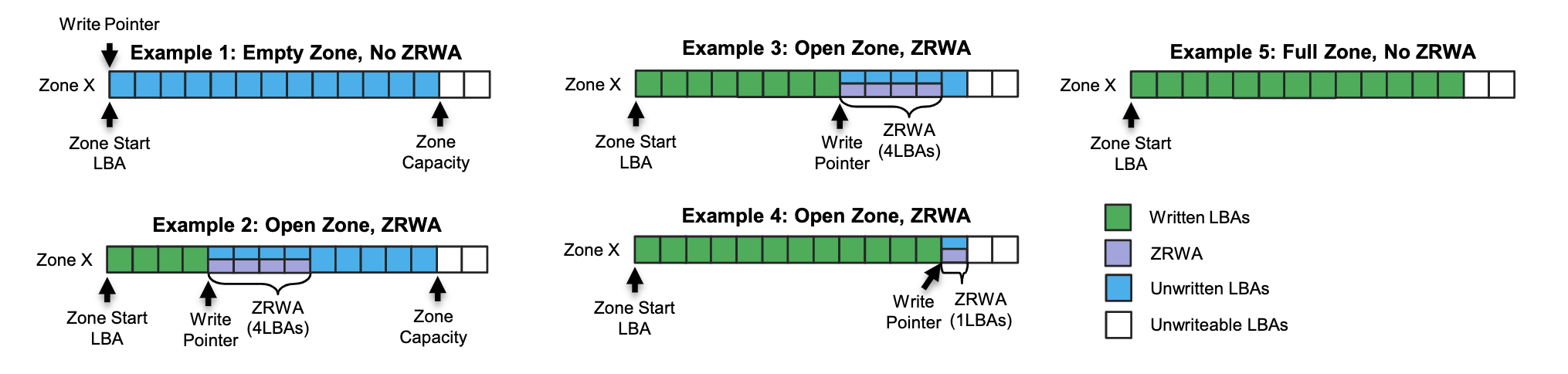
第一个扩展是Zone Random Write Area。这个我的理解是,原来只允许顺序写,这样太死板了,那就每次写的时候往前申请一小段空间,在这小段空间里,可以随机写,从而达到:1)允许就地更新,减小写放大,2)允许write的乱序写入,提高并发性。
 (图源:Zoned
Namespaces (ZNS) SSDs: Disrupting the Storage Industry)
(图源:Zoned
Namespaces (ZNS) SSDs: Disrupting the Storage Industry)
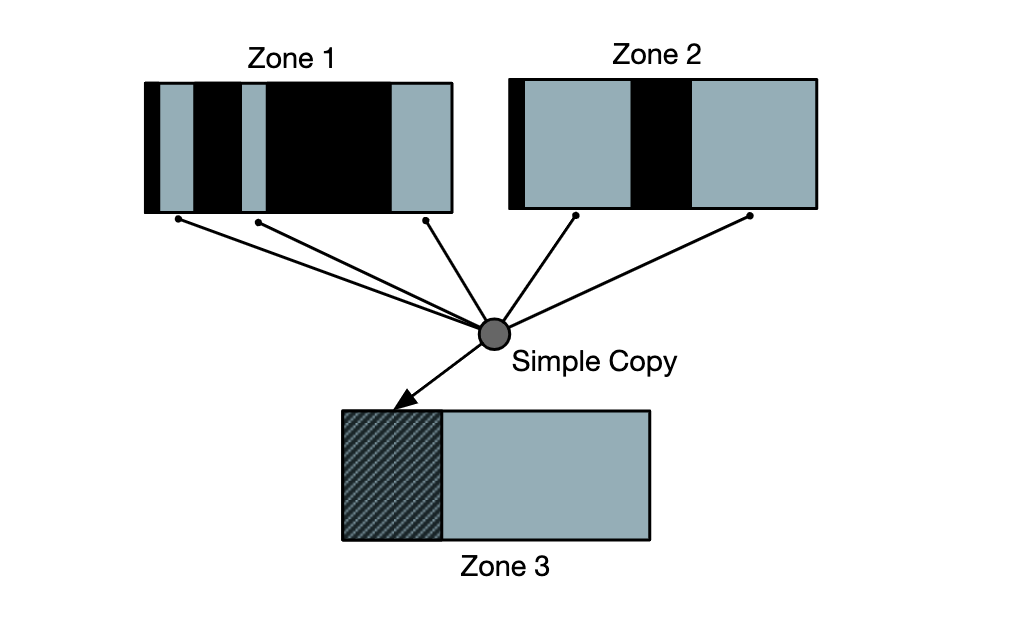
第二个扩展是Copy。对于这一个扩展,我的考虑是,在ZNS SSD中需要上层软件主动完成垃圾回收,但是这个垃圾回收每次都是要软件读数据到内存里,自己整理,再写进来,很麻烦。如果有了这一个Copy扩展,就可以将垃圾回收这个过程卸载到SSD里面,我只需要在Copy命令中指定多个在SSD中不连续的地址和长度(需要被回收的有用内容),以及一个目标地址,就可以让SSD自己完成这个垃圾回收操作。
 (图源:Zoned
Namespaces : Use Cases, Standard and Linux Ecosystem)
(图源:Zoned
Namespaces : Use Cases, Standard and Linux Ecosystem)
3. 使用Zoned Namespace的相关例子
TODO
使用Zoned Namespace接口需要系统软件和用户软件的修改和适配,这里打算放一些实际针对ZNS适配的一些例子。
- 系统软件
- f2fs
- zenfs
- 用户软件
- rocksdb
一些研究
这些文章还没看,是TODO
相关资料
- Zoned Namespace Command Set
- zonedstorage.io
- Zoned Namespaces (ZNS) SSDs
- Zoned Namespaces (ZNS) SSDs: Disrupting the Storage Industry
- Zoned Namespaces : Use Cases, Standard and Linux Ecosystem
- NVMe 命令集
- ZenFS, Zones and RocksDB - Who Likes to Take out the Garbage Anyway?
https://github.com/animeshtrivedi/notes/wiki/zns